

目录
在本文中,你将学会:
0 K-means的数学原理
1 K-means的Scikit-Learn函数解释
2 K-means的案例实战

一、K-Means原理
1.聚类简介
机器学习算法中有 100 多种聚类算法,它们的使用取决于手头数据的性质。我们讨论一些主要的算法。
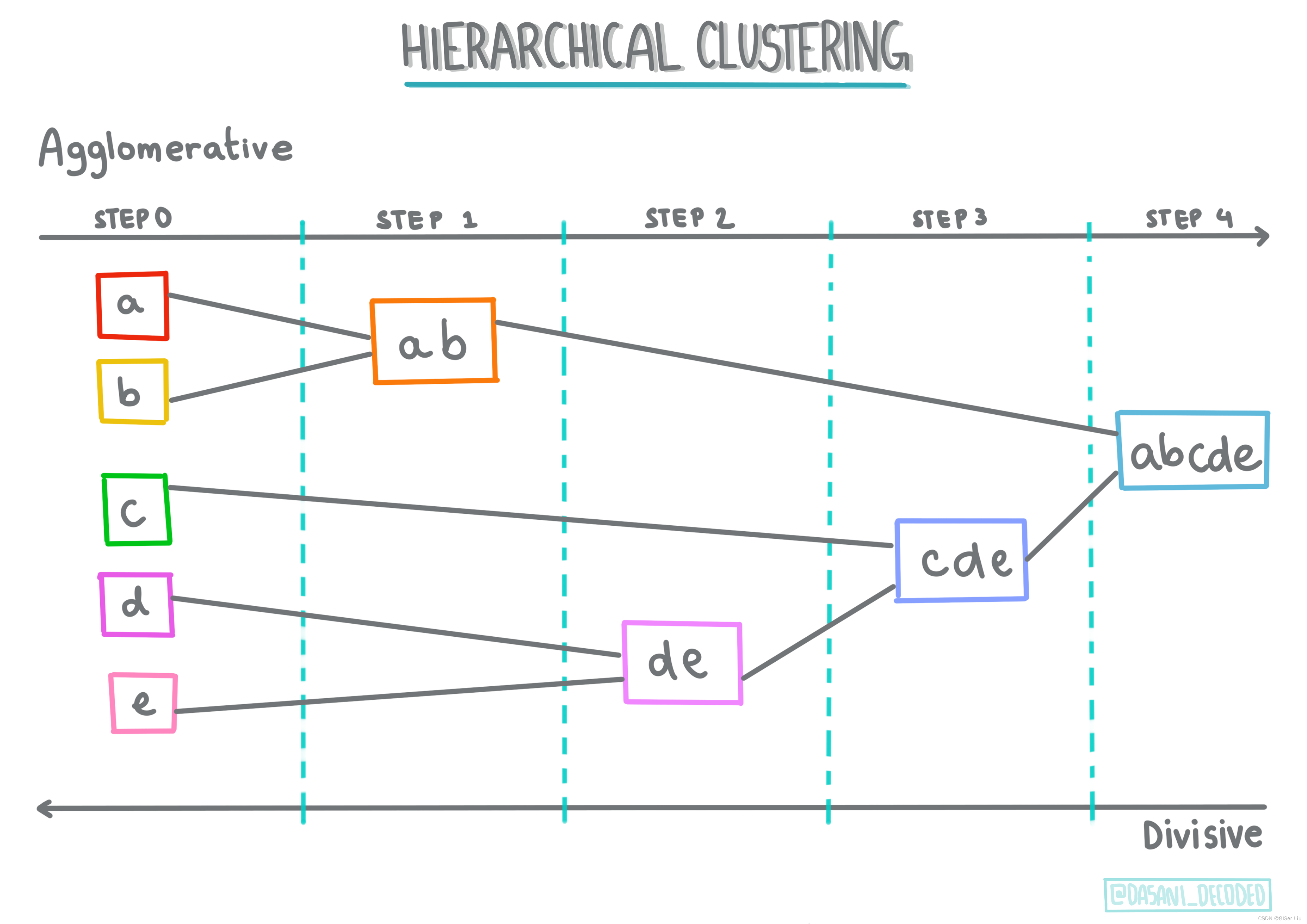
①分层聚类
分层聚类。如果一个物体是按其与附近物体的接近程度而不是与较远物体的接近程度进行分类的,则根据其成员与其他物体之间的距离形成聚类。
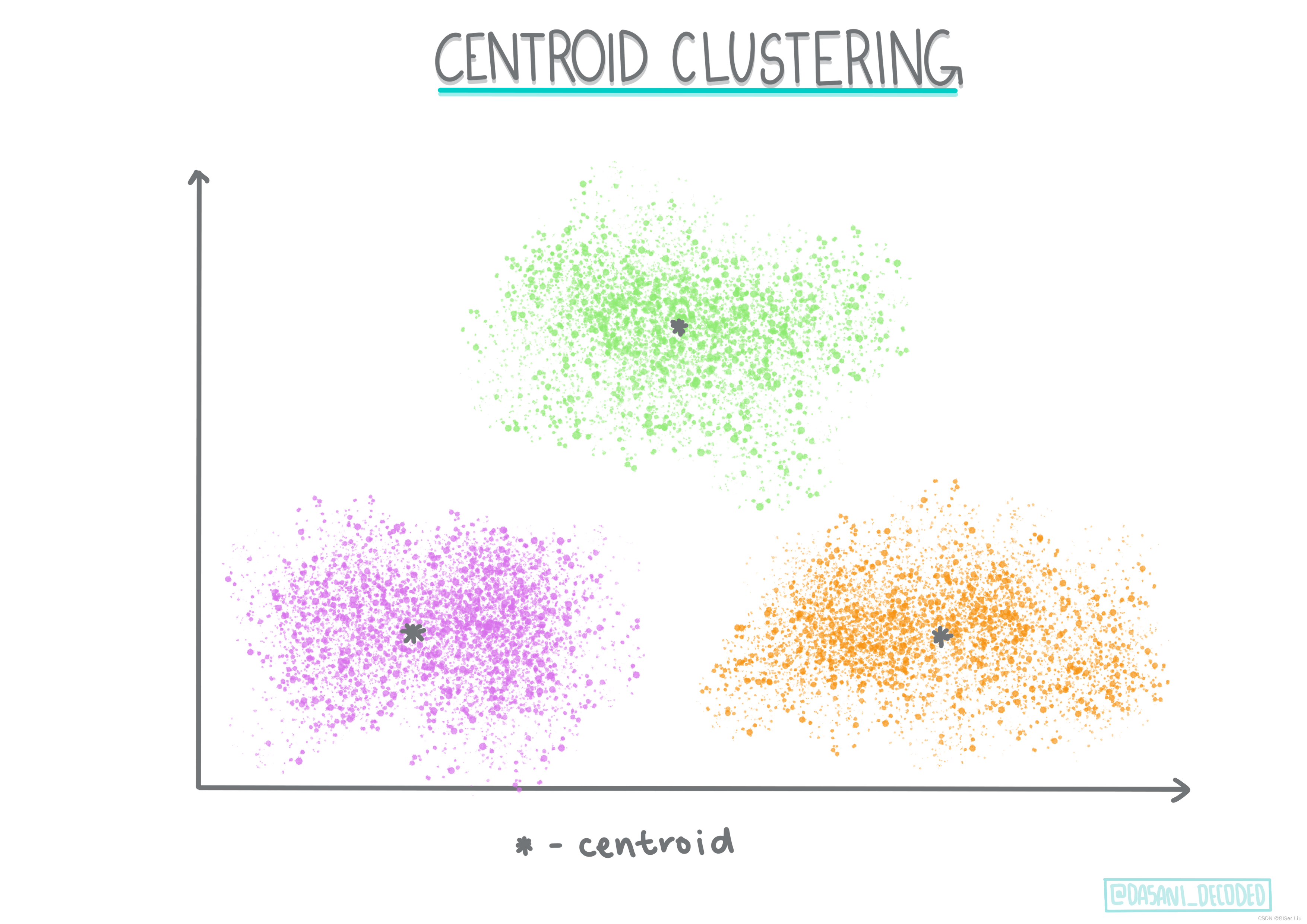
②质心聚类
质心聚类。这种流行的聚类算法需要选择K(聚类数),之后算法确定聚类的质心点并围绕该点收集数据。K 均值聚类是质心聚类的流行版本。质心由其类别所有样本点之间的均值确定,因此得名。
③其他聚类
基于分布的聚类。基于统计建模,基于分布的聚类分析侧重于确定数据点属于聚类的概率,并相应地分配它。高斯混合方法属于这种类型。
基于密度的聚类。数据点根据其密度或彼此之间的分组分配给聚类。远离组的数据点被视为异常值或噪声。DBSCAN、均值偏移等都属于这种类型的聚类。
基于网格的群集。对于多维数据集,将创建一个网格,并在网格的单元之间划分数据,从而创建聚类。
方便学习起见,本文中我们只讨论K-Means算法,其他聚类算法我会另外撰文讲解。
2.K-means的原理
先讲一个经典的K-means故事:
0 从前,有四个牧师去郊区步道,一开始牧师随便选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的居民,于是每个居民到离自己家最近的布道点去听课。
1 听课以后,大家觉得距离太远了,于是每个牧师统计了以下自己的课上所有的居民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
2 牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动后自己还不如去B牧师处听课更近,于是每个居民又去了离自己最近的布道点...就这样,牧师每个礼拜更新自己的位置,居民根据自己的情况选择布道点,最终稳定了下来。
这是K-means的计算步骤:
0 先定义总共有多少个类别(簇)
1 将每个簇心(质心)随机分配坐标位置
2 将每个样本数据点关联到离该样本点距离最近的质心上,即分配其类别
3 对于每个簇找到所有关联点的中心点(样本与质心欧氏距离的均值)
4 将该均值点作为该类别新的质心
5 如此训练,直到每个簇所拥有的点位置不在改变
🤡注意!此过程中,只有质心的位置在改变,样本点位置不变!
这是质心到样本点的欧式距离计算公式:
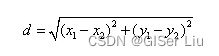
😁这个经典的故事对K均值的理解很有帮助,在故事中,牧师的位置就是质心,居民家的位置就是样本点。牧师位置的每一次调整就是 一次迭代。不同类型的K-means算法对应的距离计算方法也不同。
3.K-means的应用场景
0 分档分类器
1 物品传输优化
2 识别事件发生地点
3 用户分类
4 人员状态分析
5 保险欺诈检测
6 乘车数据分析
7 网络分析犯罪分子
8 泰森多边形
...
二、K-Means的案例实战
1.数据查看
①数据导入及结构查看
输入以下代码,将我们需要的尼日利亚音乐数据集导入notebook并查看其组织结构。
import matplotlib.pyplot as pltimport pandas as pddf = pd.read_csv("nigerian-songs.csv")#以pandas库的read_csv函数读取csv文件df.head()#查看前5行数据输出结果如下:

其中有音乐的基本信息(名称、艺术家、发布日期等),输入以下代码,查看其数据结构:
df.info()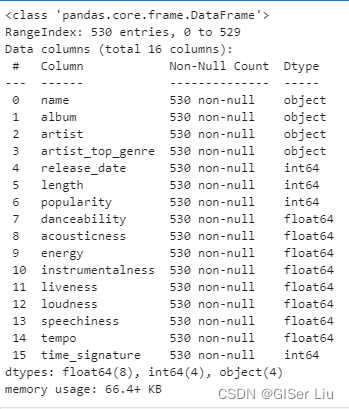
可以看到,尼日利亚音乐数据集中共包含539行样本。有16个待选择数据特征:数值型数据有12个,字符型数据有4个。
②查看数据描述
输入以下代码查看数据描述:
df.describe()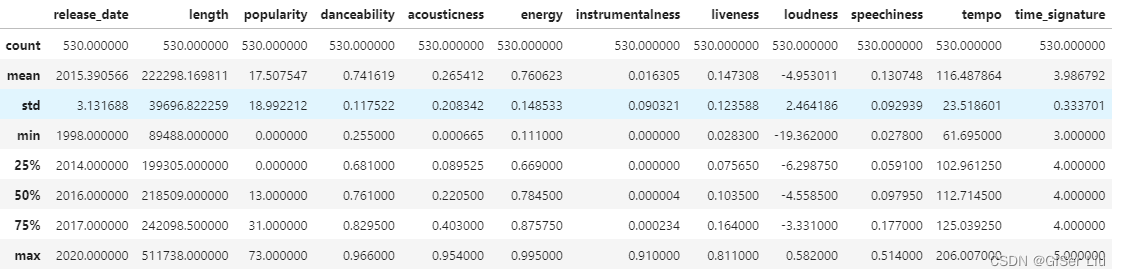 通过查看数据的描述,我们可以看到不同数据特征的数量、均值、方差及不同层次的数值。这些信息可以帮助我们在后面的处理中选择合适的模型或处理方法。
通过查看数据的描述,我们可以看到不同数据特征的数量、均值、方差及不同层次的数值。这些信息可以帮助我们在后面的处理中选择合适的模型或处理方法。
🤔如果我们使用的是聚类分析,这是一种不需要标记数据的无监督方法,为什么我们需要这些信息?在数据探索阶段,它们会派上用场!
2.数据可视化及预处理
可视化数据,直观查看数据的特征。本次作者使用seaborn库来可视化,seaborn库是基于matplotlib库封装的,可视化效果更棒!😀
在此之前我们去掉数据中包含缺失值的样本,避免其影响。查看数据是否有缺失值或异常值,输入以下代码:
df.isnull().sum()
可以看到,本次数据比较干净,没有缺失值。我们开始可视化!😏
①条形图
输入以下代码查看数据集中数量前5名的艺术家类型数量的条形图:
import seaborn as sns#导入seaborn包top = df['artist_top_genre'].value_counts()#对不同音乐家类型进行统计汇总,格式为列表plt.figure(figsize=(10,7))#设置图表大小sns.barplot(x=top[:5].index,y=top[:5].values)#取出前5行数据的index作为X轴类型,音乐数量作为Y轴数值绘制条形图plt.xticks(rotation=45)#若X轴标签过长导致可视化效果不好,可进行标签旋转进行调整plt.title('Top genres',color = 'blue')#设置条形图标题内容及颜色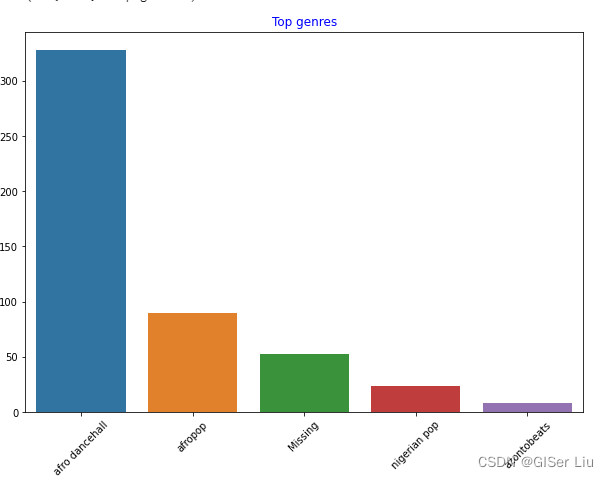
可以看到,前5种风格类型中,afro dancehall风格音乐数量最多;眼尖的同学可能发现,其中有一部分数据是“Missing”,这表示这部分数据是没有类型标签的,方便分析起见,我们将这一部分数据抛弃掉!
在大部分数据集中,🤨类似于"Missing"类型的数据在缺失值筛选中并不容易被发现,但它们常常占据着较大部分,我们可以对这些特征绘制条形图来发现它们并进行剔除!😜
继续对全部数据进行可视化。输入以下代码:
df = df[df['artist_top_genre'] != 'Missing']#删去没有音乐风格标签的数据top = df['artist_top_genre'].value_counts()#统计不同音乐风格的音乐数量plt.figure(figsize=(10,7))#设置画布尺寸sns.barplot(x=top.index,y=top.values)#对所有音乐风格数据的标签和数量绘制条形图plt.xticks(rotation=45)#调整X轴标签角度plt.title('Top genres',color = 'blue')#设置标题属性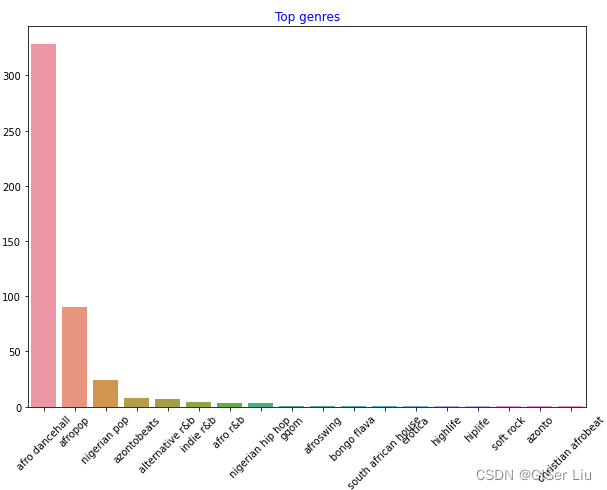
如此一来,不同风格的音乐数据便清晰的展现出来。
为了方便我们的聚类实验,我们提取出数量最多的三类样本及人气大于0的样本作为数据集主体用于之后的聚类。输入以下代码:
df = df[(df['artist_top_genre'] == 'afro dancehall') | (df['artist_top_genre'] == 'afropop') | (df['artist_top_genre'] == 'nigerian pop')]#提取数量前三的样本df = df[(df['popularity'] > 0)]#提取人气大于0的样本②热力图
做一个快速测试,看看数据中哪些特征之间存在高度相关。我们对经过筛选的数据进行相关系数计算,并以热力图的方式呈现相关性。输入以下代码 :
corrmat = df.corr()#用于计算相关系数f, ax = plt.subplots(figsize=(12, 9))#subplots() 函数既创建了一个包含子图区域的画布,又创建了一个 figure 图形对象。sns.heatmap(corrmat, vmax=.8, square=True)#corrmat值为相关系数,vmax为最大相关系数值用来界定颜色的映射范围,square为bool类型参数,是否使热力图的每个单元格为正方形,默认为False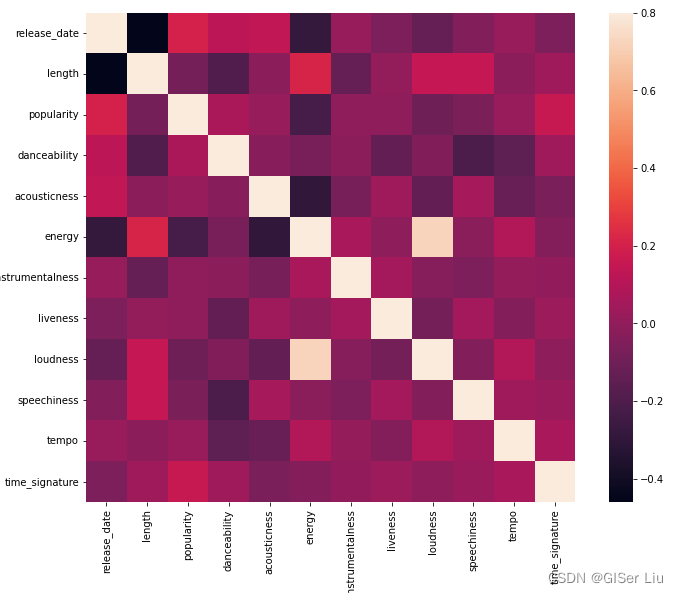
排除矩阵对角线上的相关性(自己与自己本来就高度相关),我们可以看到energy和loudness特征相关形较高。这并不奇怪,因为嘈杂的音乐通常充满激情。
🙄请注意,相关性并不意味着因果关系!我们证明它们相关,但不能证明他们之间的因果关系。
③核密度图
根据它们的受欢迎程度,这三种流派在可跳舞性的看法上是否显着不同?以音乐数据的人气为X轴,以是否可跳舞性为Y轴绘制核密度(KDE)图查看数据的分布。输入以下代码:
sns.set_theme(style="ticks")#set_style( )是用来设置主题的,Seaborn有五个预设好的主题: darkgrid , whitegrid , dark , white ,和 ticks g = sns.jointplot(#jointplot函数用于绘制双变量图 data=df,#数据为经过筛选预处理的数据 x="popularity", y="danceability", hue="artist_top_genre",#选择两个变量, 增加hue变量将为图形添加条件颜色,并在边沿轴上绘制单独的密度曲线 kind="kde",#设置绘图类型 KDE指核密度图)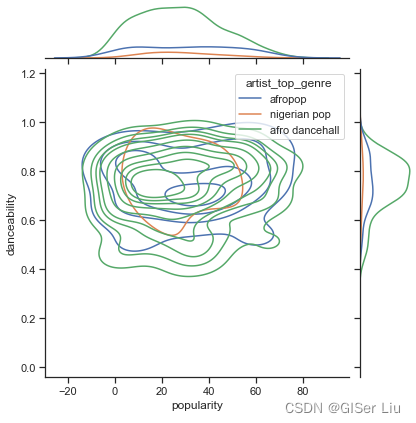
在数据探索阶段我们可以自由去探寻不同特征之间的关系,如果你觉得繁琐 你也可以用批处理函数来快速查看结果,尽管这样少了很多趣味性。🙄
从图上看,这三种流派在人气和可舞蹈性方面松散地对齐。 这说明我们对它进行聚类时将比较麻烦,数据差异太小。
④散点图
我们继续对这两个特征创建散点图查看数据分布。输入以下代码:
sns.FacetGrid(df, hue="artist_top_genre", size=5) \ .map(plt.scatter, "popularity", "danceability") \ .add_legend()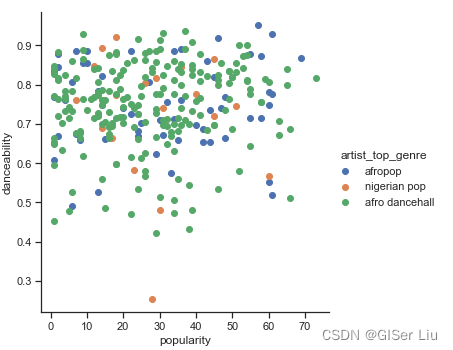
嗯哼,验证了我们上面的猜想,数据分布很复杂,乱糟糟的😅。
对于聚类分析,我们通常可以使用散点图来直观地显示数据聚类,掌握这种类型的可视化非常有用。
⑤箱型图
对于混乱的数据,我们可以使用箱型图来直观的查看数据的分布,从中找出异常数据并进行排除。输入以下代码查看不同数值型特征的箱型图分布:
plt.figure(figsize=(20,20), dpi=200)plt.subplot(4,3,1)#subplot函数划分了4行3列的画布区域,第三个参数表示图像在其中的位置sns.boxplot(x = 'popularity', data = df)plt.subplot(4,3,2)sns.boxplot(x = 'acousticness', data = df)plt.subplot(4,3,3)sns.boxplot(x = 'energy', data = df)plt.subplot(4,3,4)sns.boxplot(x = 'instrumentalness', data = df)plt.subplot(4,3,5)sns.boxplot(x = 'liveness', data = df)plt.subplot(4,3,6)sns.boxplot(x = 'loudness', data = df)plt.subplot(4,3,7)sns.boxplot(x = 'speechiness', data = df)plt.subplot(4,3,8)sns.boxplot(x = 'tempo', data = df)plt.subplot(4,3,9)sns.boxplot(x = 'time_signature', data = df)plt.subplot(4,3,10)sns.boxplot(x = 'danceability', data = df)plt.subplot(4,3,11)sns.boxplot(x = 'length', data = df)plt.subplot(4,3,12)sns.boxplot(x = 'release_date', data = df)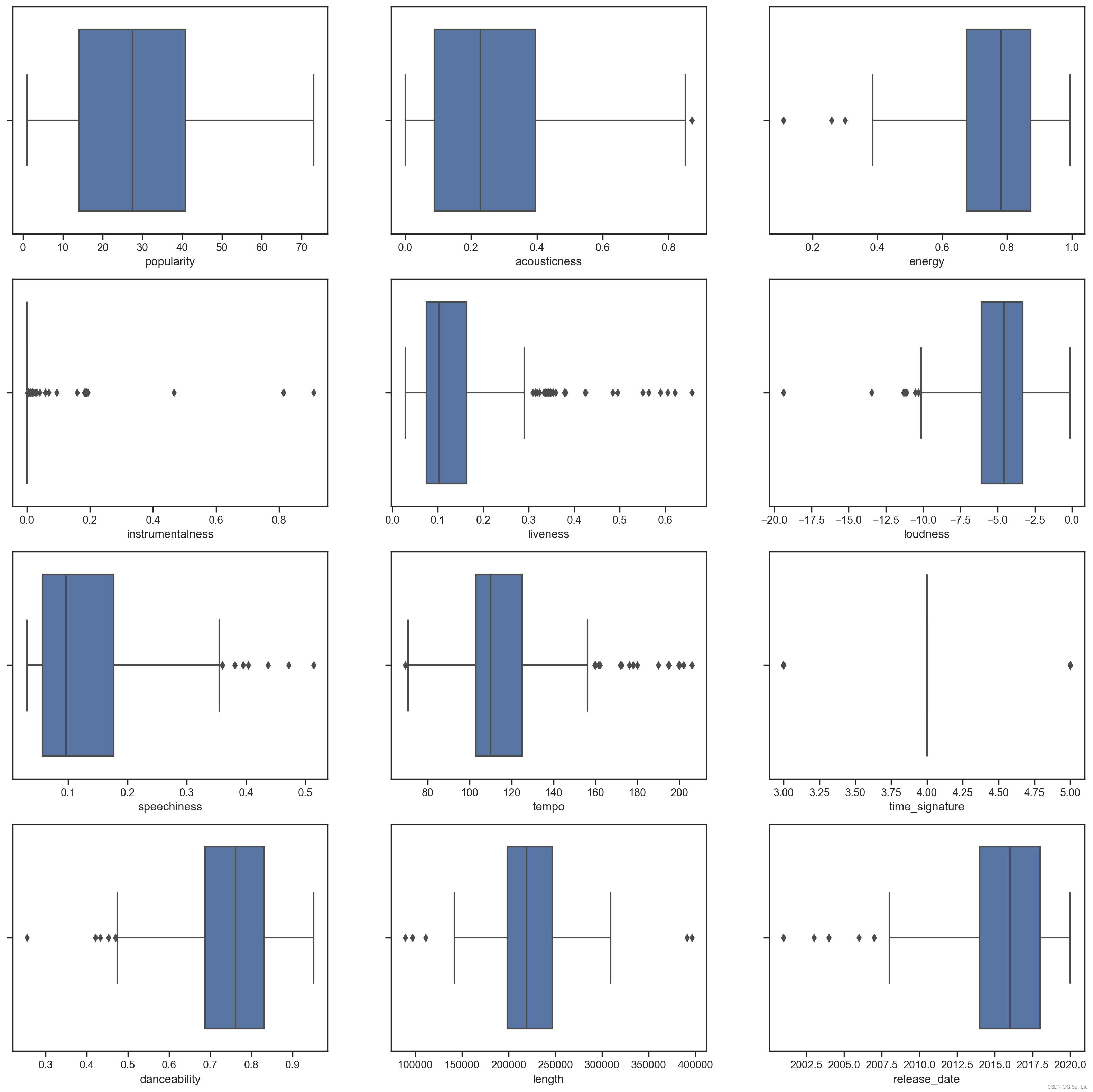
我们可以看到,*星号表示异常值,箱体的位置表示数据的分布区域。图中大量特征是分布不均匀的,异常值较多的样本特征不适合聚类,我们可以对其进行进一步剔除。
3.模型训练与精度评价
①样本选择
现在,选择将用于聚类分析练习的特征列。这些特征列需要具有相似的范围;且其中的文本列数据需要编码为数值数据:
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()#创建一个编码器X = df.loc[:,('artist_top_genre','popularity','danceability','acousticness','loudness','energy')]#loc为Selection by Label函数,即为按标签取数据;将需要的标签数据取出作为X训练特征样本y = df['artist_top_genre']#将艺术家流派作为Y验证模型精度标签X['artist_top_genre'] = le.fit_transform(X['artist_top_genre'])#对文本数据进行标签化为数值格式y = le.transform(y)#对文本数据进行标签化为数值格式②模型训练
现在,我们需要选择聚类的集群(簇)数量。我们已知可以从中取出3种歌曲类型,因此我们将nclusters赋值为3,输入以下代码:
from sklearn.cluster import KMeansnclusters = 3 #初始化质心数量,因为我们想要划分3中音乐类型,因此将其赋值为3seed = 0 #选择随机初始化种子km = KMeans(n_clusters=nclusters, random_state=seed)#一个random_state对应一个质心随机初始化的随机数种子。如果不指定随机数种子,则 sklearn中的KMeans并不会只选择一个随机模式扔出结果km.fit(X)#对Kmeans模型进行训练#使用训练好的模型进行预测y_cluster_kmeans = km.predict(X)y_cluster_kmeans
该数组即K-means模型的预测结果,其中数字为每行样本的的聚类结果(0、1 或 2)。
③精度评价
我们接着使用此预测结果计算“轮廓系数”,输入以下代码:
from sklearn import metricsscore = metrics.silhouette_score(X, y_cluster_kmeans)# metrics.silhouette_score函数用于计算轮廓系数score0 轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。
最佳值为1,最差值为-1。接近0的值表示重叠的群集。负值通常表示样本已分配给错误的聚类,因为不同的聚类更为相似.
1 轮廓系数的公式为:S=(b-a)/max(a,b),其中a是单个样本离同类簇所有样本的距离的平均数,b是单个样本到不同簇所有样本的平均。
轮廓系数表示了同类样本间距离最小化,不同类样本间距离最大的度量
![]()
我们的模型轮廓系数是0.54,这表明我们的数据不是特别适合这种类型的聚类,但这不影响我们的教学,实践工作中总是有各种各样的麻烦。我们接着进行训练:
④模型调参
导入第三方库,调整参数进行新一轮训练,我们对簇的数量进行批处理,看看参数值为多少效果最佳:
from sklearn.cluster import KMeanswcss = []for i in range(1, 11): kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42) kmeans.fit(X) wcss.append(kmeans.inertia_)参数介绍:
0 range():这里用for循环是为了迭代训练轮数,这里我们设置训练10轮
1 random_state:确定初始化质心的随机数生成。
2 wcss:用于存储“聚类内平方和”测量聚类内所有点到聚类质心的平方平均距离。
3 inertia_:K-Means算法试图选择质心来最小化“惯性”,“衡量内部相干聚类的尺度”。该值在每次迭代时都会追加到 wcss 变量中。这个评价参数表示的是簇中某一点到簇中距离的和,这种方法虽然在评估参数最小时表现了聚类的精细性
4 k-means++:在Scikit-learn中,你可以使用'k-means++'优化,它“初始化质心(通常情况下)彼此相距较远,可能比随机初始化有更好的结果。
我们使用lineplot函数绘制随着类别(簇)数量的增加,inertia_参数值变化趋势的折线图。
plt.figure(figsize=(10,5))sns.lineplot(range(1, 11), wcss,marker='o',color='red')plt.title('Elbow')plt.xlabel('Number of clusters')plt.ylabel('WCSS')plt.show()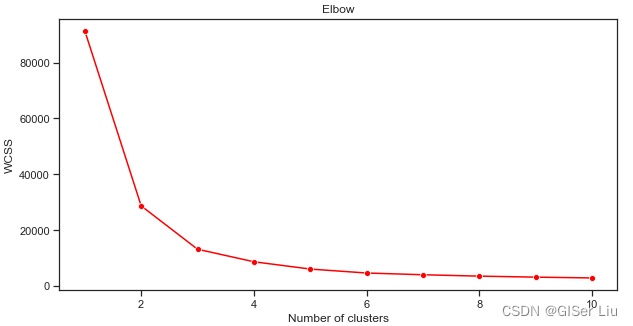
从这幅图可以看出,K均值算法当簇数为3时,其inertia_参数效果较好,我们可以选择3类或4类对数据集进行二次预测,评估其精度。
再次尝试模型训练与精度评价过程,这次设置3轮聚类,并将聚类结果以散点图显示:
from sklearn.cluster import KMeanskmeans = KMeans(n_clusters = 3)#设置聚类的簇(类别)数量kmeans.fit(X)#对模型进行训练labels = kmeans.predict(X)#输出预测值plt.scatter(df['popularity'],df['danceability'],c = labels)#以人气为X轴,可舞蹈性为Y轴,标签为类别绘制散点图plt.xlabel('popularity')plt.ylabel('danceability')plt.show()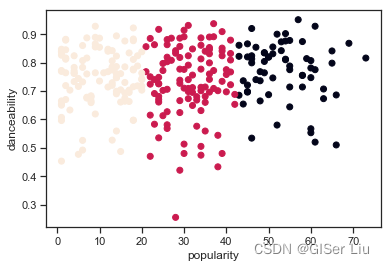
嗯?😥
输入以下代码检查模型的准确度:
labels = kmeans.labels_#提取出模型中样本的预测值labelscorrect_labels = sum(y == labels)#统计预测正确的值print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size))print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))![]()
可以看出,尽管我们调整了参数;所有样本中,只有38%的样本被成功预测了,换句话说,我们的K-means模型并不好。🤨但现实大部分情况就是这样,分析的方法我已经交给你了,或许你可以选择其他特征或其他的聚类模型来进一步提高模型的性能😀。
三、结论
在本文中,我们学习了K-means算法的数学原理,作者以尼日利亚音乐数据集为案例。带你了解了如何通过可视化的方式发现数据中潜在的特征。最后对训练好的K-means模型进行了评估。

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
系列文章推荐
机器学习系列0 机器学习思想_GISer Liu的博客-CSDN博客
机器学习系列1 机器学习历史_GISer Liu的博客-CSDN博客
机器学习系列2 机器学习的公平性_GISer Liu的博客-CSDN博客_公平机器学习
机器学习系列3 机器学习的流程_GISer Liu的博客-CSDN博客
机器学习系列4 使用Python创建Scikit-Learn回归模型_GISer Liu的博客-CSDN博客
机器学习系列5 利用Scikit-learn构建回归模型:准备和可视化数据(保姆级教程)_GISer Liu的博客-CSDN博客
机器学习系列6 使用Scikit-learn构建回归模型:简单线性回归、多项式回归与多元线性回归_GISer Liu的博客-CSDN博客_多元多项式回归机器学习系列7 基于Python的Scikit-learn库构建逻辑回归模型_GISer Liu的博客-CSDN博客机器学习系列8 基于Python构建Web应用以使用机器学习模型_GISer Liu的博客-CSDN博客
来源地址:https://blog.csdn.net/qq_45590504/article/details/125287189









