
前言
最近做性能测试,需要模拟生产环境的数据量,在造百万、千万级数据的时候发现直接使用插入sql效率极低,百度了一翻,找到几种方式,但用下来还是有很快速的方式,推荐第四种
插入mysql数据效率对比
1.单行插入
insert into tableName (colunm1,colunm2,...) value(value1,value2,...);没错,很普通的一条sql,插入速度也很普通,不推荐
2.多行插入
insert into tableName(colunm1,colunm2,..) values(value1,value2...),(value1,value2...);有点点进度,但是不多,多行插入可以减少插入数据时的IO和网络开销,从而加快插入数据的速度。此方法适用于插入少量数据的情况,当插入数据量变大时,数据库连接可能会被打满
3.批量插入
INSERT INTO table_name (column1, column2, column3)VALUES(value1, value2, value3),(value4, value5, value6),......ON DUPLICATE KEY UPDATE column1=VALUES(column1), column2=VALUES(column2), column3=VALUES(column3);这个操作将所有插入放在一个事务中,并将其视为一个操作。此方法使用一次SQL查询来插入大量数据,因此减少了IO和网络开销
4.使用LOAD DATA INFILE语句
LOAD DATA INFILE 'file_name'INTO TABLE table_nameFIELDS TERMINATED BY ','LINES TERMINATED BY '\n';使用LOAD DATA INFILE语句可以将大量的数据快速地导入MySQL中。此方法适用于数据已存储在文件中的情况,您只需指定文件名和目标表即可导入数据。而且,此方法支持多线程操作,可在不阻塞数据库的同时并行地导入数据
说实话,这种方式非常香,亲测500W数据1分钟插入完成,推荐
file_name: 本地存储数据的文件
这个文件的数据需要先准备好,你也可以选择像我一样代码生成
- 首先,从数据库复制一条数据
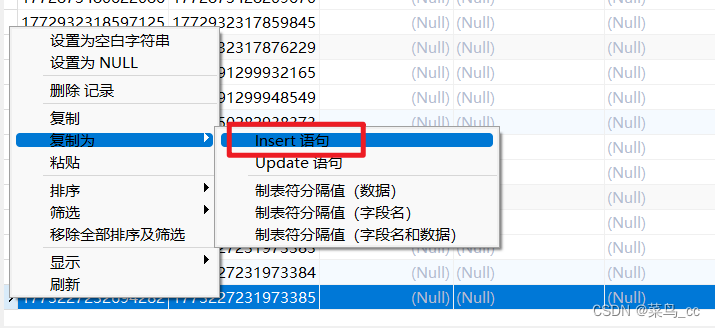
- 然后把复制出来的插入sql中value里的内容抠出来
- 抠出来的内容注意下是否有外键、主键,如果有要处理一下扣出来的内容,下面的例子是id是主键,我给去掉了,然后循环生成主键拼接上去,循环生成的值要符合数据库的字段定义类型
data = ",860272,'2023-07-26 18:00:03','2023-07-26 18:00:03',1,未完成,时,1,1时,219,85,1,001-001,0,9784,'2023-07-26 18:00:03',9784,'2023-07-26 18:00:03'"with open('demo.txt', 'w+', encoding='utf-8') as f: for i in range(0, 1000000): f.write(str(i + 1) + data + '\n')- 执行后生成demo.txt文件,每一行不同的值逗号分隔
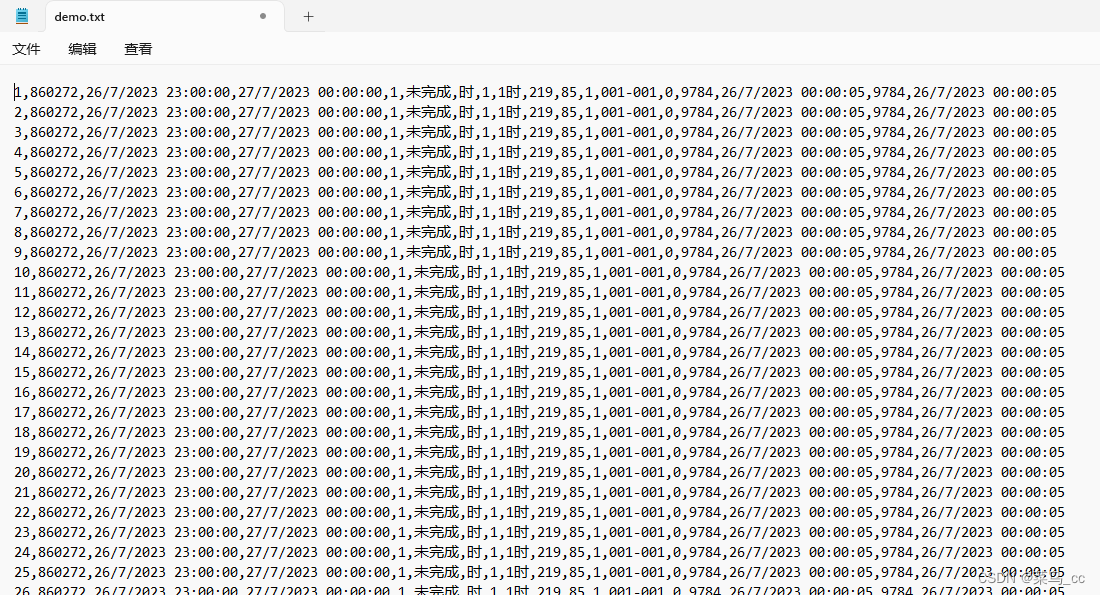
- 最后,连接数据库,可以使用命令连接,也可以借助工具连接,执行命令
LOAD DATA LOCAL INFILE 'E:\\demo.txt' INTO TABLE 表名FIELDS TERMINATED BY ',' ('列名1','列名2','列名3','列名4')注意:你的txt的值要跟命令中的列名对应上,如果你是全字段的值插入,那么('列名1','列名2','列名3','列名4')可以省略不写
好了,可以享受插入数据的快乐了…
来源地址:https://blog.csdn.net/m0_58160096/article/details/131946520











