
这篇文章主要介绍“Python中Pandas文件操作和读取CSV参数的方法是什么”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python中Pandas文件操作和读取CSV参数的方法是什么”文章能帮助大家解决问题。
一、Pandas 读取文件
当使用 Pandas 做数据分析的时,需要读取事先准备好的数据集,这是做数据分析的第一步。Panda 提供了多种读取数据的方法,针对不同的文件格式,有以下几种:
(1) read_csv() 用于读取文本文件。
(2) read_excel() 用于读取文本文件。
(3) read_json() 用于读取 json 文件。
(4) read_sql_query() 读取 sql 语句的。
其通用的流程如下:
(1) 导入库 import pandas as pd。
(2) 找到文件所在位置(绝对路径 = 全称)(相对路径 = 和程序在同一个文件夹中的路径的简称)。
(3) 变量名 = pd.读写操作方法(文件路径,具体的筛选条件,……)。
二、CSV 文件读取
CSV 又称逗号分隔值文件,是一种简单的文件格式,以特定的结构来排列表格数据。 CSV 文件能够以纯文本形式存储表格数据,比如电子表格、数据库文件,并具有数据交换的通用格式。CSV 文件会在 Excel 文件中被打开,其行和列都定义了标准的数据格式。
将 CSV 中的数据转换为 DataFrame 对象是非常便捷的。和一般文件读写不一样,它不需要你做打开文件、读取文件、关闭文件等操作。相反,您只需要一行代码就可以完成上述所有步骤,并将数据存储在 DataFrame 中。
下面进行实例演示,源数据如下:
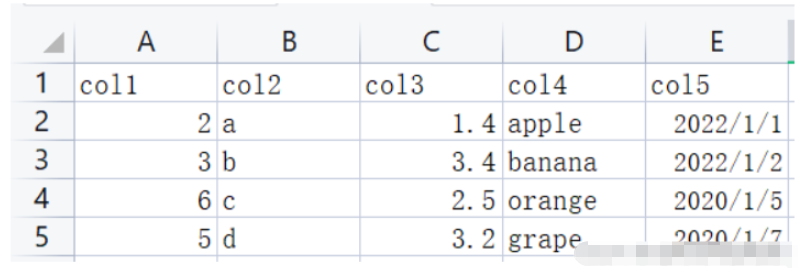
首先,我们对 CSV 文件进行读取,可以通过相对路径,也可以通过 os 动态取得绝对路径 os.getcwd() os.path.json。
import pandas as pddf = pd.read_csv("./data/my_csv.csv")print(df,type(df))# col1 col2 col3 col4 col5#0 2 a 1.4 apple 2022/1/1#1 3 b 3.4 banana 2022/1/2#2 6 c 2.5 orange 2022/1/5#3 5 d 3.2 grape 2022/1/7 <class 'pandas.core.frame.DataFrame'>我们可以通过 os.getcwd() 读取文件的存储路径。
import osos.getcwd()#'C:\\Users\\CQB\\Desktop\\内蒙农业大学数据分析教案和代码\\第16天'其语法模板如下:
read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, usecols=None, squeeze=None, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False,cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)1. 基本参数
(1) filepath_or_buffer(数据输入的路径):可以是文件路径、可以是 URL,也可以是实现 read 方法的任意对象。这个参数,就是我们输入的第一个参数。
我们可以直接 read_csv 读取我们想要的文件。
import pandas as pdpd.read_csv(r"data\students.csv")#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12还可以是一个 URL,如果访问该 URL 会返回一个文件的话,那么 pandas 的 read_csv函 数会自动将该文件进行读取。比如:我们服务器上放的数据,将刚才的文件返回。
但需要注意的是,他需要网络请求,因此读取文件比较慢。
pd.read_csv("http://my-teaching.top/static/data/students.csv")里面还可以是一个 _io.TextIOWrapper,其中,pandas 默认使用 utf-8 读取文件,比如:
f = open(r"data\students.csv", encoding="utf-8")pd.read_csv(f)#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12(2) sep:读取 csv 文件时指定的分隔符,默认为逗号。注意:csv 文件的分隔符和我们读取 csv 文件时指定的分隔符一定要一致。
import pandas as pdpd.read_csv(r"data\students_step.csv")#id|name|address|gender|birthday#01|朱梦雪|地球村|女|2004/11/2#12|许文博|月亮星|女|2003/8/7#23|张兆媛|艾尔星|女|2004/11/2#34|付延旭|克哈星|男|2003/10/11#45|王杰|查尔星|男|2002/6/12#56|董泽宇|塔桑尼斯|男|2002/2/12由于指定的分隔符和 csv 文件采用的分隔符不一致,因此多个列之间没有分开,而是连在一起了。 所以,我们需要将分隔符设置成 \t 才可以。
df = pd.read_csv(r"data\students_step.csv", sep="|")df#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12(3) delim_whitespace:默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、\t 等等。不管分隔符是什么,只要是空白字符,那么可以通过 delim_whitespace=True 进行读取。如下,我们对 delim_whitespace 不设置,也就是默认为 False,会发现读取有点问题。
df = pd.read_csv(r"data\students_whitespace.txt", sep=" ")df#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博\t月亮星女2003/8/7NaN#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰\t查尔星男2002/6/12NaN#56董泽宇\t塔桑尼斯男2002/2/12NaN对此,我们将 delim_whitespace 设置为 True,便会得到我们想要的读取结果。
df = pd.read_csv(r"data\students_whitespace.txt", delim_whitespace=True)df#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12(4) header:用作列名的行号,以及数据的开头。
默认行为是推断列名:如果没有传递任何名称,则该行为与 header=0 相同,并且从文件的第一行推断列名,如果显式传递列名,则该行为与 header=None 相同。
显式传递 header=0 以替换现有名称。可以是整数列表,指定列上多索引的行位置,例如 [0,1,3]。未指定的中间行将被跳过(例如,本例中跳过 2 行)。
这里需要注意,如果 skip_blank_lines=True,此参数将忽略注释行和空行,因此 header=0 表示数据的第一行,而不是文件的第一行。
(5) names:当 names 没被赋值时,header 会变成 0,即选取数据文件的第一行作为列名;当 names 被赋值,header 没被赋值时,那么 header 会变成 None。如果都赋值,就会实现两个参数的组合功能。
(a) names 没有被赋值,header 也没赋值:
这种情况下,header 为 0,即选取文件的第一行作为表头。
pd.read_csv(r"data\students.csv")#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12(b) names 没有被赋值,header 被赋值:
如果不指定 names,指定 header 为 1,则选取第二行当做表头,第二行下面为数据。
pd.read_csv(r"data\students.csv", header=1)#1朱梦雪地球村女2004/11/2#02许文博月亮星女2003/8/7#13张兆媛艾尔星女2004/11/2#24付延旭克哈星男2003/10/11#35王杰查尔星男2002/6/12#46董泽宇塔桑尼斯男2002/2/12(c) names 被赋值,header 没有被赋值:
pd.read_csv(r"data\students.csv", names=["编号", "姓名", "地址", "性别", "出生日期"])#编号姓名地址性别出生日期#0idnameaddressgenderbirthday#11朱梦雪地球村女2004/11/2#22许文博月亮星女2003/8/7#33张兆媛艾尔星女2004/11/2#44付延旭克哈星男2003/10/11#55王杰查尔星男2002/6/12#66董泽宇塔桑尼斯男2002/2/12可以看到,names 适用于没有表头的情况,指定 names 没有指定 header,那么 header 相当于 None。
一般来说,读取文件的时候会有一个表头,一般默认是第一行,但是有的文件中是没有表头的,那么这个时候就可以通过 names 手动指定、或者生成表头,而文件里面的数据则全部是内容。
所以这里 id、name、address、date 也当成是一条记录了,本来它是表头的,但是我们指定了 names,所以它就变成数据了,表头是我们在 names 里面指定的。
(a) names 和 header 都被赋值:
pd.read_csv(r"data\students.csv", names=["编号", "姓名", "地址", "性别", "出生日期"], header=1)#编号姓名地址性别出生日期#02许文博月亮星女2003/8/7#13张兆媛艾尔星女2004/11/2#24付延旭克哈星男2003/10/11#35王杰查尔星男2002/6/12#46董泽宇塔桑尼斯男2002/2/12这个时候,相当于先不看 names,只看 header,header 为 0 代表先把第一行当做表头,下面的当成数据;然后再把表头用 names 给替换掉。
names 和 header 的使用场景主要如下:
(1) csv 文件有表头并且是第一行,那么 names 和 header 都无需指定;
(2) csv 文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定 header 即可;
(3) csv 文件没有表头,全部是纯数据,那么我们可以通过 names 手动生成表头;
(4) csv 文件有表头、但是这个表头你不想用,这个时候同时指定 names 和 header。先用 header 选出表头和数据,然后再用 names 将表头替换掉,就等价于将数据读取进来之后再对列名进行 rename。
(6) index_col:我们在读取文件之后所得到的 DataFrame 的索引默认是 0、1、2……,我们可以通过 set_index 设定索引,但是也可以在读取的时候就指定某列为索引。
df = pd.read_csv(r"data\students.csv", index_col="birthday")df# id name address gender#birthday#2004/11/21朱梦雪地球村女#2003/8/72许文博月亮星女#2004/11/23张兆媛艾尔星女#2003/10/114付延旭克哈星男#2002/6/125王杰查尔星男#2002/2/126董泽宇塔桑尼斯 男也可以用来删除指定列。
df.index=df['birthday']del df['birthday']df# idnameaddressgender#birthday#2004/11/21朱梦雪地球村女#2003/8/72许文博月亮星女#2004/11/23张兆媛艾尔星女#2003/10/114付延旭克哈星男#2002/6/125王杰查尔星男#2002/2/126董泽宇塔桑尼斯男我们在读取的时候指定了 name 列作为索引; 此外,除了指定单个列,还可以指定多列作为索引,比如 [“id”, “name”]。同时,我们除了可以输入列名外,还可以输入列对应的索引。比如:“id”、“name”、“address”、"date"对应的索引就分别是 0、1、2、3。
df2 = pd.read_csv(r"data\students.csv", index_col=["gender","birthday"])df2# idnameaddress#genderbirthday#女2004/11/21朱梦雪地球村# 2003/8/72许文博月亮星# 2004/11/23张兆媛艾尔星#男2003/10/114付延旭克哈星# 2002/6/125王杰查尔星# 2002/2/126董泽宇塔桑尼斯使用 loc 删选也是同样的道理。
df2.loc["女"]# idnameaddress#birthday#2004/11/21朱梦雪地球村#2003/8/72许文博月亮星#2004/11/23张兆媛艾尔星(7) usecols:返回列的子集。
如果是类似列表的,则所有元素都必须是位置性的(即文档列中的整数索引),或者是与用户在名称中提供的列名或从文档行推断的列名相对应的字符串。如果给出了名称,则不考虑文档行。
pd.read_csv(r"data\students.csv", usecols=["name","birthday"])# name#0朱梦雪#1许文博#2张兆媛#3付延旭#4王杰#5董泽宇2. 通用解析参数
(1) encoding:表示这只编码格式,utf-8,gbk。
pd.read_csv(r"data\students_gbk.csv") # UnicodeDecodeError如果提示错误喂 UnicodeDecodeError —> 需要想到编码问题。
pandas 默认使用 utf-8 格式读取。
pd.read_csv(r"data\students_gbk.csv", encoding="gbk") #idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12(2) dtype:在读取数据的时候,设定字段的类型。
比如,公司员工的 id 一般是:00001234,如果默认读取的时候,会显示为 1234,所以这个时候要把他转为字符串类型,才能正常显示为 00001234。
df = pd.read_csv(r"data\students_step_001.csv", sep="|")df#idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12我们将 id 的数据类型设置为字符串,便可以显示为 001 之类的。
df = pd.read_csv(r"data\students_step_001.csv", sep="|", dtype ={"id":str}) df#idnameaddressgenderbirthday#0001朱梦雪地球村女2004/11/2#1002许文博月亮星女2003/8/7#2003张兆媛艾尔星女2004/11/2#3004付延旭克哈星男2003/10/11#4005王杰查尔星男2002/6/12#5006董泽宇塔桑尼斯男2002/2/12(3) converters:在读取数据的时候对列数据进行变换.
例如将 id 增加 10,但是注意 int(x),在使用 converters 参数时,解析器默认所有列的类型为 str,所以需要进行类型转换。
pd.read_csv('data\students.csv', converters={"id": lambda x: int(x) + 10})#idnameaddressgenderbirthday#011朱梦雪地球村女2004/11/2#112许文博月亮星女2003/8/7#213张兆媛艾尔星女2004/11/2#314付延旭克哈星男2003/10/11#415王杰查尔星男2002/6/12#516董泽宇塔桑尼斯男2002/2/12(4) true_values 和 false_values:指定哪些值应该被清洗为 True,哪些值被清洗为 False。
我们以性别为例,男设置为 True,女设置为 False。
pd.read_csv('data\students.csv', true_values=['男'], false_values=['女'])# idnameaddressgenderbirthday#01朱梦雪地球村False2004/11/2#12许文博月亮星False2003/8/7#23张兆媛艾尔星False2004/11/2#34付延旭克哈星True2003/10/11#45王杰查尔星True2002/6/12#56董泽宇塔桑尼斯True2002/2/12这里的替换规则为,只有当某一列的数据类别全部出现在 true_values + false_values 里面,才会被替换。
(5) skiprows:表示过滤行,想过滤掉哪些行,就写在一个列表里面传递给 skiprows 即可。注意的是,这里是先过滤,然后再确定表头,比如:
pd.read_csv('data\students.csv', skiprows=[0,3])# 1朱梦雪地球村女2004/11/2#02许文博月亮星女2003/8/7#14付延旭克哈星男2003/10/11#25王杰查尔星男2002/6/12#36董泽宇塔桑尼斯男2002/2/12这里把第一行过滤掉了,因为第一行是表头,所以在过滤掉之后第二行就变成表头了。 当然里面除了传入具体的数值,来表明要过滤掉哪些行,还可以传入一个函数。
pd.read_csv('data\students.csv', skiprows=lambda x: x > 0 and x % 2 == 0)# idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#13张兆媛艾尔星女2004/11/2#25王杰查尔星男2002/6/12由于索引从 0 开始,所以凡是索引大于 0、并且%2 等于 0 的记录都过滤掉。索引大于 0,是为了保证表头不被过滤掉。
(6) skipfooter:表示从文件末尾过滤行。
pd.read_csv('data\students.csv', skipfooter=1)上述代码运行后会出现报错,并且表格中的数据都变成乱码,具体原因下方有解释。
pd.read_csv('data\students.csv', skipfooter=1, engine="python", encoding="utf-8")# idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12pandas 解析数据时用的引擎,目前解析引擎有两种:c、python。默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。
skipfooter 接收整型,表示从结尾往上过滤掉指定数量的行,因为引擎退化为 python,那么要手动指定 engine=“python”,不然会警告。另外需要指定 encoding=“utf-8”,因为 csv 存在编码问题,当引擎退化为 python 的时候,在 Windows 上读取会乱码。
(7) nrows:表示设置一次性读入的文件行数,在读入大文件时很有用,比如 16G 内存的 PC 无法容纳几百 G 的大文件。
pd.read_csv('data\students.csv', nrows=3)# idnameaddressgenderbirthday#01朱梦雪地球村女2004/11/2#12许文博月亮星女2003/8/7#23张兆媛艾尔星女2004/11/23. 空值处理相关参数
na_values:该参数可以配置哪些值需要处理成 NaN。
pd.read_csv('data\students.csv', na_values=["女", "朱梦雪"]) #idnameaddressgenderbirthday#01NaN地球村NaN2004/11/2#12许文博月亮星NaN2003/8/7#23张兆媛艾尔星NaN2004/11/2#34付延旭克哈星男2003/10/11#45王杰查尔星男2002/6/12#56董泽宇塔桑尼斯男2002/2/12可以看到将女和朱梦雪设置成了NaN,这里的情况是不同的列中包含了不同的值。
4. 时间处理相关参数
parse_dates:指定某些列为时间类型,这个参数一般搭配 date_parser 使用。
date_parser:是用来配合 parse_dates 参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式。
df = pd.read_csv('data\students.csv')df.dtypes#id int64#name object#address object#gender object#birthday object#dtype: object我们通过 parse_dates 将 birthday 设置为时间类型。
df = pd.read_csv('data\students.csv', parse_dates=["birthday"])df.dtypes#id int64#name object#address object#gender object#birthday datetime64[ns]#dtype: object5. 分块读入相关参数
(1) iterator:迭代器,iterator 为 bool 类型,默认为 False。
如果为 True,那么返回一个 TextFileReader 对象,以便逐块处理文件。这个在文件很大、内存无法容纳所有数据文件时,可以分批读入,依次处理。
chunk = pd.read_csv('data\students.csv', iterator=True)chunk#<pandas.io.parsers.TextFileReader at 0x1b27f00ef88>我们已经对文件进行了分块操作,可以先提取出前两行。
print(chunk.get_chunk(2))# id name address gender birthday#0 1 朱梦雪 地球村 女 2004/11/2#1 2 许文博 月亮星 女 2003/8/7文件还剩下四行,但是我们指定读取100,那么也不会报错,不够指定的行数,那么有多少返回多少。
print(chunk.get_chunk(100))# id name address gender birthday#2 3 张兆媛 艾尔星 女 2004/11/2#3 4 付延旭 克哈星 男 2003/10/11#4 5 王杰 查尔星 男 2002/6/12#5 6 董泽宇 塔桑尼斯 男 2002/2/12这里需要注意的是,在读取完毕之后,再读的话就会报错了。(2) chunksize:整型,默认为 None,设置文件块的大小。chunksize 还是返回一个类似于迭代器的对象,当我们调用 get_chunk,如果不指定行数,那么就是默认的 chunksize。
chunk = pd.read_csv('data\students.csv', chunksize=2)print(chunk) print(chunk.get_chunk())#<pandas.io.parsers.TextFileReader object at 0x000001B27F05C5C8># id name address gender birthday#0 1 朱梦雪 地球村 女 2004/11/2#1 2 许文博 月亮星 女 2003/8/7我们再使用两次 print(chunk.get_chunk()) 就可以分步读取出所有的数据,因为这里的 chunksize 设置为 2。
我们也可以指定 chunk.get_chunk() 的参数。
以上便是 pandas 的 read_csv 函数中绝大部分参数了,同时其中的部分参数也适用于读取其它类型的文件。
其实在读取 csv 文件时所使用的参数不多,很多参数平常我们都不会用到的,不过不妨碍我们了解一下,因为在某些特定的场景下它们是可以很方便地帮我们解决一些问题的。
个人感觉分块读取这个参数最近在工作中提高了很大的效率。
关于“Python中Pandas文件操作和读取CSV参数的方法是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注编程网行业资讯频道,小编每天都会为大家更新不同的知识点。










