
python2.x版本的字符编码有时让人很头疼,遇到问题,网上方法可以解决错误,但对原理还是一知半解,本文主要介绍 python 中字符串处理的原理,附带解决 json 文件输出时,显示中文而非 unicode 问题。首先简要介绍字符串编码的历史,其次,讲解 python 对于字符串的处理,及编码的检测与转换,最后,介绍 python 爬虫采取的 json 数据存入文件时中文输出的问题。
参考书籍:Python网络爬虫从入门到实践 by唐松
在python 2或者3 ,字符串编码只有两类 :
(1)通用的Unicode编码;
(2)将Unicode转化为某种类型的编码,如UTF-8,GBK;
1、计算机历史:
计算机只处理数字,因此处理文本时,必须转换成数字才行。
8位(bit)=1字节(byte)=256种不同状态=从000000到111111;
1GB=1024M=1024(1024kb)=1024(1024(1024b));
ASCII编码 是对应英文字符与二进制数字之间的关系;ASCII一共规定了128种,如大写字母A是65,即01000001;可见一字母一字节;
GB2312编码 简体中文常见的编码,两个字节代表一个中文汉字 ,理论上256*256个编码,即可表示65536种中文字;
各国编码不同,为了各国能扩平台进行文本的转换与处理,Unicode就被作为统一码或者单一码。Unicode编码通常是两个字节,unicode与ASCII编码的区别,在于unicode在ASCII编码前加了一个0,即字母A的ASCII编码为01000001,unicode编码即为0000000001000001;但英文字母其实只用一个字节就够了,unicode编码写英文时多了一个字节,浪费存储空间。因而unicode开发了通用转换格式(Unicode Transformation Format(UTF)),常见的有utf-8或者utf-16;
2、python字符编码
参考地址:https://www.jb51.net/article/139878.htm
(1)encode的作用是,将unicode对象编码成其他编码的字符串,str.encode('utf-8'),编码成UTF-8;(2)decode的作用是将其他编码的字符串转换成Unicode编码,str.decode('UTF-8');
- import chardet 查阅具体的编码类型,
chardet.detect(str),但是str不能是unicode编码类型,但是该方法 不接受 本来已经是unicode的编码的 参数,会有TypeError: Expected object of type bytes or bytearray, got: <type 'unicode'>错误; - 作为统一标准,unicode不能再被解码,如果UTF-8想转至其他非unicode,则必须(2)先decode 到unicode,在encode到其他非unicode的编码。
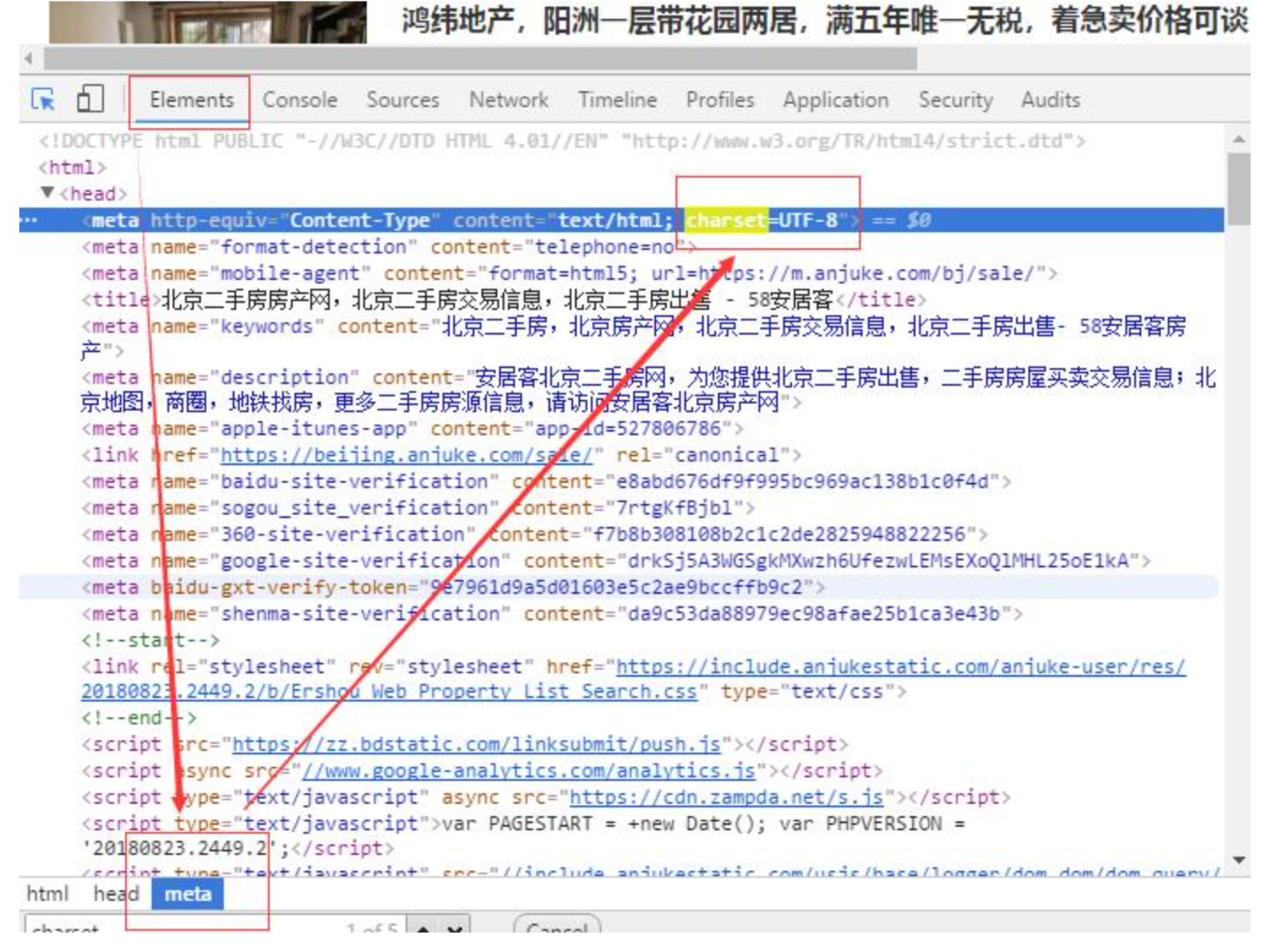
爬取网页时,可在F12 elements meta中查看网页编码方式,如图:
(2)中文,Python中的字典能够被序列化到json文件中存入json
with open("anjuke_salehouse.json","w",encoding='utf-8') as f:
json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4);
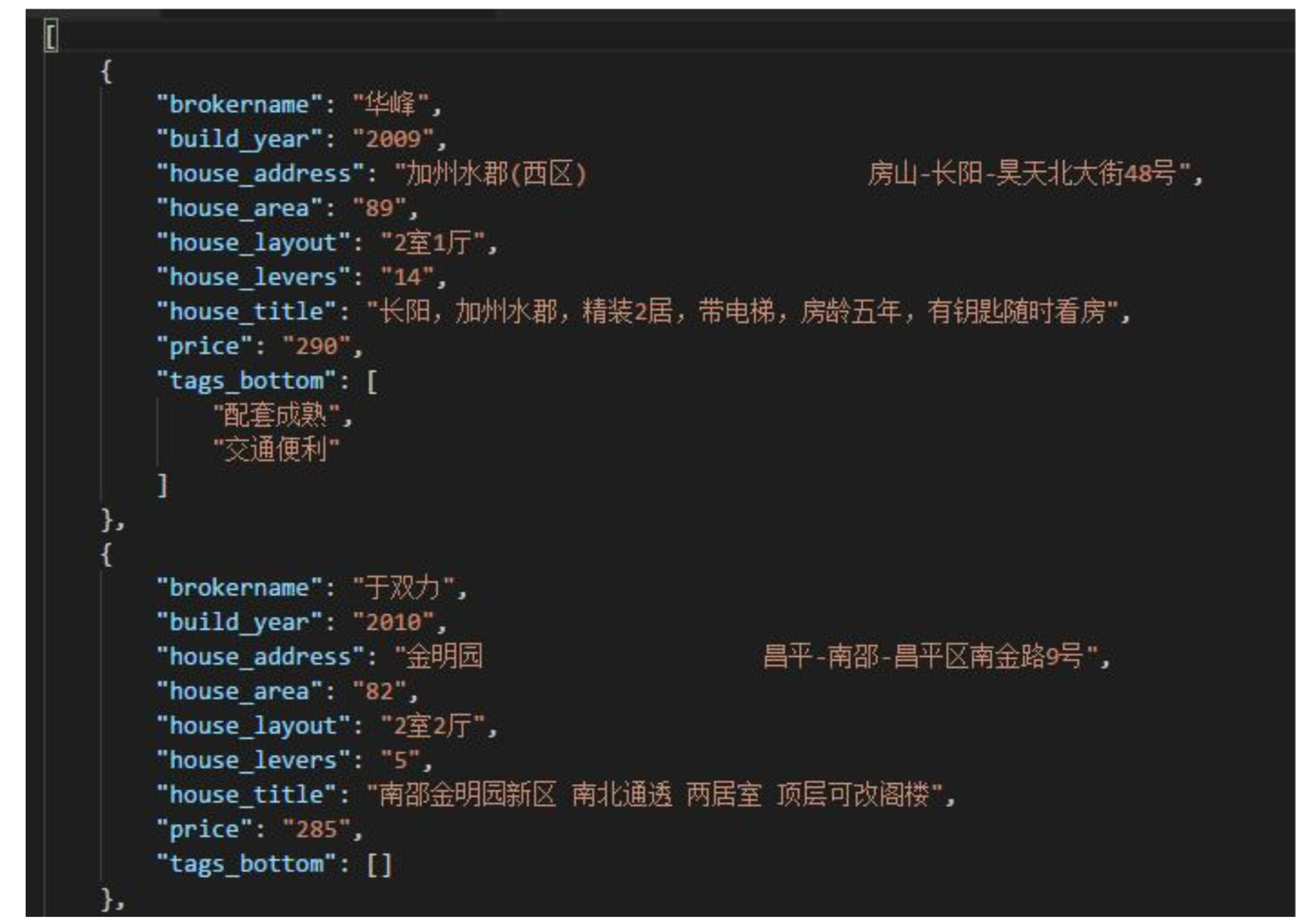
print(u'加载入文件完成...');存储数据如图:
- dump()的第一个参数是要序列化的对象,第二个参数是打开的文件句柄,注意文件打开
open()时加上以UTF-8编码打开,在dump()的时候也加上ensure_ascii=False,不然会变成ascii码写到json文件中json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4)
json.dumps()/json.loads()等用法
json_str = json.dumps(all_house,ensure_ascii=False); #all——books 为列表、字典等python自带的数据结构,将其写成json
#print json_str; #[{"brokername": "王东宇"},{},{}]
new_dict = json.loads(json_str);#主要是读json文件时,需要用到
#print new_dict; #{u'house_area': u'95', u'build_year': u'2005'}- json.dumps() 是将一个Python数据结构转换为一个JSON编码的字符串,
{"name": "xiaoming"}
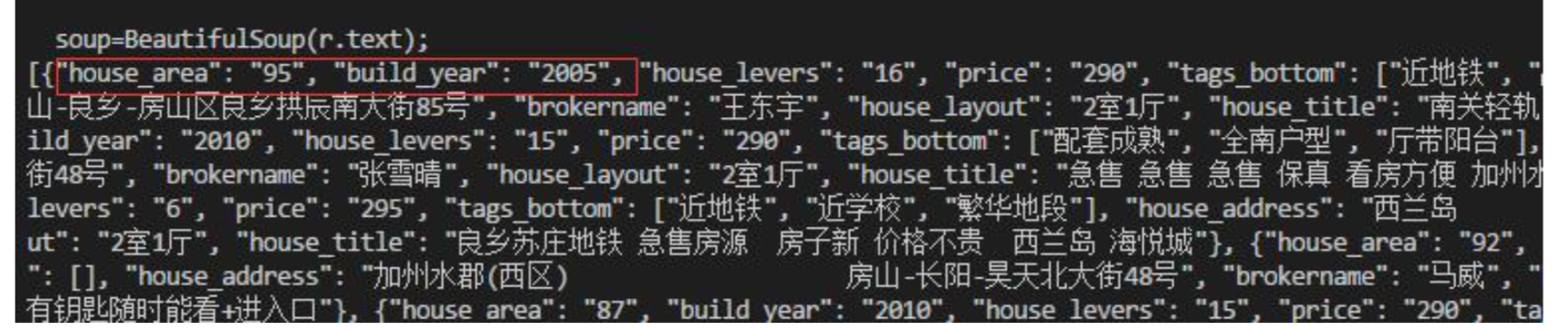
json.loads() 是将一个JSON编码的字符串(字典形式)转换为一个Python数据结构,{u'name': u'xiaoming'}

dumps转化后键与值都变成了双引号,而在loads后变成python变量时,元素都变成了单引号,并且字符串前加多了个u。
一般要求当要字符串通过loads转为python数据类型时,得外层用单引号,里面元素key和value用双引号。
- sort_keys:根据key排序
dump与dumps的区别
-
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw);dump将一个对象序列化存入文件,dump需要一个类似于文件指针的参数(并不是真的指针,可称之为类文件对象),可以与文件操作结合,也就是说可以将dict转成str存入文件中,如json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4)中的f表示一个数据待写入的json文件句柄; -
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw);而dumps(str)直接给的是str,也就是直接将字典转成str,无需写入文件,类似一个数据格式的转换方法,将python字符串转成json字典。 - 所以dumps是将dict转化成str格式,loads是将str转化成dict格式。
dump和load也是类似的功能,只是与文件操作结合起来了。
(3)中文存入txt
f=open('net_saving_data.txt','w',encoding='utf-8');
for item in all_house:
# house_area=item['house_area'];
# price=item['price'];
output='\t'.join([str(item['house_area']),str(item['price']),str(item['build_year']),str(item['house_title'])]);
f.write(output);
f.write('\n');
f.close();
- 在2.7.15版本的python中,提示错误
TypeError: 'encoding' is an invalid keyword argument for this function,无法传入encoding的参数,但是在3.7版本可传入encoding='utf-8'参数,即可对 txt进行中文写入。
- 中文写入txt、json文件是无非就是open()文件时,需要添加utf-8,dump()时,需要添加ensure_ascii=False,防止ascii编码,但是刚开始因为python版本是2.7.15,不是3.7,导致存储不成功的时候,一直以为是代码的问题。所以最后发现就是版本的问题,也挺伤的。网上关于中文这个编码问题有很多,但是他们都没有强调python版本的问题!!!其他3.xx的版本没有试过。
- 读取网页数据的时候,查看网页的charset,及chardet库对编码类型的查询,及时进行decode和encode的编码转化,应该就能避免很多编码问题了。其他的坑以后踩了再补吧。









