
小编给大家分享一下Python ORM框架中的SQLAlchemy怎么用,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
一、SQLAlchemy 介绍
1.1 ORM 的概念
ORM全称Object Relational Mapping(对象关系映射),通过 ORM 就能使用 python 中的对象操作数据库(在底层转换为sql语句),免去sql语句的书写。
但是,由于抽象程度较高,所以 sql 语句的执行效率比较低,因此有些情况下,还是需要我们亲自书写sql语句。
ORM 是通过以下对应关系,将 python 代码转换为 sql 语句的:
| python对象 | 关系型数据库 |
|---|---|
| 类 | 表 |
| 类属性 | 字段 |
| 类的实例对象 | 记录 |
| 实例对象的属性值 | 记录的字段值 |
1.2 SQLAlchemy介绍
在 django 中访问数据库,通常会使用 django 自带的 ORM(Object Relational Mapping)对象关系映射来访问数据库,只需要用python的语法来操作对象,就能被自动映射为 sql 语句。
而 SQLAlchemy 则是一个专门的对象关系映射器和 Python SQL工具包,旨在实现高效和高性能的数据库访问。
1.3 架构
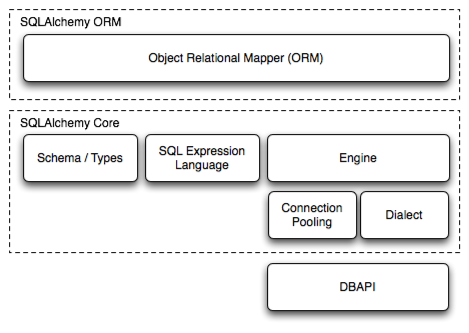
Schema / Types: 类到表之间的映射规则。
SQL Expression Language :SQL 语句。
Engine :引擎。
Connection Pooling: 连接池。
Dialect: 方言,调用不同的数据库
API(Oracle, postgresql, Mysql) 并执行对应的 SQL语句。
1.4 异步
SQLAlchemy 在1.4版本之前,通过 greenlet 实现对异步的支持,而在1.4及之后版本中,添加了 python asyncio 标准库的支持。所以,这需要 python 解释器版本在 3.6+。
1.5 安装
安装 SQLAlchemy(1.4版本):
pip install SQLAlchemy如果需要 greenlet 异步支持:
pip install sqlalchemy[asyncio]二、SQLAlchemy 快速入门
2.1 创建配置(可选)
这一步不是必要的,但将配置单独放置一个文件中,能方便我们管理和修改。
创建一个配置文件,如 settings.py:
DBMS = 'mysql' # 数据库管理系统名称:如 sqlite、mysql、oracle等 DBAPI = 'pymysql' # 所使用的 DBAPI(第三方驱动程序),如 pysqlite、pymysql 等# 下面就是数据库管理系统的内容:主机IP、端口、用户名、密码、数据库HOST = 'localhost' PORT = 3306 USERNAME = 'root'PASSWORD = '123456'DB = 'myclass'DB_URI = f'{DBMS}+{DBAPI}://{USERNAME}:{PASSWORD}@{HOST}:{PORT}/{DB}'2.2 创建引擎和获取、关闭连接
任何 SQLAlchemy 应用程序的开始都是一个名为 Engine 的对象,它是一个为特定的数据库服务器创建一次的全局对象,可以理解为通过 SQLAlchemy 操作数据库的连接中心,保存着连接池。
from sqlalchemy import create_enginefrom settings import DB_URIengine = create_engine(DB_URI) # 创建引擎# 也可以直接传入字符串,不使用配置文件# engine = create_engine("数据库管理系统名称+驱动://用户名:密码@主机IP:端口号/数据库名称", echo=True, future=True)conn = engine.connect() # 获取连接result = conn.execute('SQL语句') # 执行SQLprint(result.fetchone()) # 打印 SQL 执行结果中的一行conn.close() # 关闭连接create_engine()的其他常用参数:
echo:设置为 True,表示将 SQL 记录到记录器,该记录器将 SQL 写入标准输出。
future:使用2.0风格的引擎和连接 API,以便使用 2.0 版本中的新特性。
encoding:默认为 utf-8。
pool_size:在连接池中保持打开的连接数。
2.3 创建 ORM 模型
from sqlalchemy.orm import declarative_basefrom sqlalchemy import Column, Integer, String# 创建基类Base = declarative_base()# 每一个模型类都要继承 declarative_base() 创建的基类class User(Base): # 定义表名 __tablename__ = 'users' # 定义字段,参数为字段类型和约束 id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String) age = Column(Integer) sex = Column(String(10))2.4 创建会话
每次在 python 中执行完操作后,都需要通过 session 提交到数据库:
from sqlalchemy.orm import sessionmaker# 创建会话,相当于 Django ORM 的 objectsSession = sessionmaker(bind=engine)session = Session()# 执行数据的增删改查……# 比如,新增数据# session.add(模型类(类属性=值,……))# 提交session.commit()# 关闭sessionsession.close()在commit()之前,可以取消对实例对象所做的修改,也就是回滚:
session.rollback()2.5 创建和删除表
创建所有表:
Base.metadata.create_all(engin)删除所有表:
Base.metadata.drop_all(engin)2.6 新增数据
新增数据:
变量名 = 模型类(类属性=值,……)
session.add(变量名)
批量新增:
session.add_all([
模型类(类属性=值,……),
模型类(类属性=值,……)
……
])
2.7 查询数据
查询所有:
变量名 = session.query(模型类).all()
返回模型类实例对象列表。
查询指定字段:
变量名 = session.query(模型类.字段).all()
只获取返回结果的第一个:
变量名 = session.query(模型类).first()
连表查询:
变量名 = session.query(模型类1,模型类2).filter(条件).all()
# 如,查询用户 ID 及其爱好的 IDres = session.query(User, Hobby).filter(User.hobby_id == Hobby.id).all()返回一个元组构成的列表,元组包含两个实例对象。
过滤:
变量名 = session.query(模型类).filter(条件).all()
# 如,查询年龄大于18岁的学生名字res = session.query(Student.name).filter(Student.age >= 18).all()条件中常用运算符:
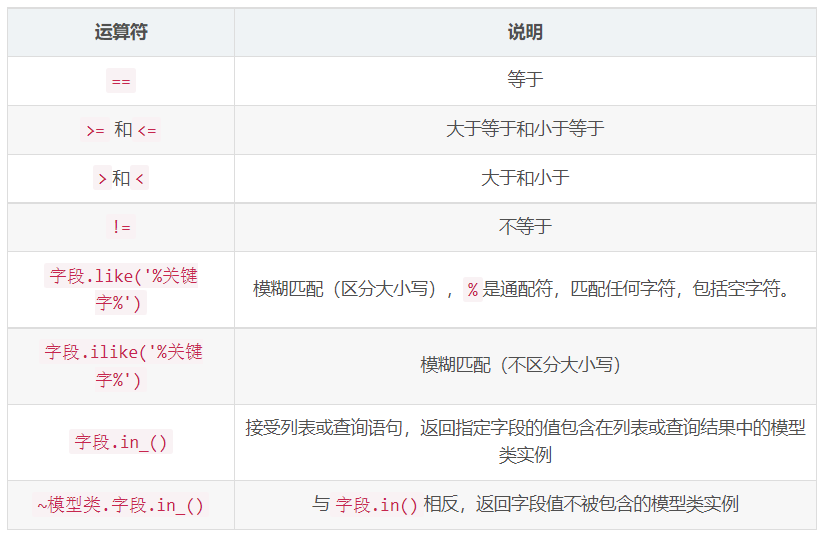
多条件过滤:
# 条件之间默认为 and 关系变量名 = session.query(模型类).filter(条件1, 条件2……).all()# 使用 or from sqlalchemy import or_变量名 = session.query(模型类).filter(or_(条件1, 条件2……)).all()排序:
变量名 = session.query(模型类).order_by(排序依据字段.desc()).all() # desc 表示倒序,写 asc 或不写就是升序
统计个数:
变量名 = session.query(模型类).count()
切片:
变量名 = session.query(模型类).all()[1:3]
2.8 修改数据
变量名 = session.query(模型类).filter(条件).update({"字段":值})
# 不要忘记提交
2.9 删除数据
session.query(模型类).filter(条件).delete()
三、多表操作
下面的内容中,我将称定义了外键字段的模型类为被关联模型,另一个为关联模型。
3.1 一对多
创建模型:
外键定义在多的一方。
from sqlalchemy import ForeignKeyfrom sqlalchemy.orm import relationshipclass 模型类名称(Base): __tablename__ = '表名' 字段 = Column(类型,约束) …… 外键字段 = Column(类型,其他约束,ForeignKey(关联模型.字段)) # 重点 关联模型名称小写 = relationship("关联模型的名称",backref="用于反向查询的名称") # 不是字段,不会在数据库中创建新增数据:
# 正向新增
变量名 = 被关联模型(字段=值,……,外键字段=关联模型(字段=值……))
session.add(变量名)
# 反向新增
变量名A = 关联模型(字段=值,……)
变量名A.backref的值 = [被关联模型的实例1,被关联模型的实例2……]
session.add(变量名A)
正向查询:
先获取被关联模型的实例,然后通过实例.外键获取关联对象。
反向查询:
先获取关联模型的实例,然后通过实例.backref的值获取被关联模型的实例对象。
3.2 多对多
创建模型:
新建中间表,只保存双方的对应关系即可。
在其中一方,定义 relationship:
关联模型类名称小写 = relationship("关联模型类的名称", secondary='中间表模型类的名称小写', backref="用于反向查询的名称") # 不是字段,不会在数据库中创建
新增数据:
在双方创建好数据后,直接在中间表中添加对应关系。
正向、反向查询:
与一对多模型一致。
看完了这篇文章,相信你对“Python ORM框架中的SQLAlchemy怎么用”有了一定的了解,如果想了解更多相关知识,欢迎关注编程网行业资讯频道,感谢各位的阅读!












