
这篇文章主要讲解了“Redis整数集合的使用方法有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Redis整数集合的使用方法有哪些”吧!
一、集合概述
对于集合,STL 的 set 相信大家都不陌生,它的底层实现是红黑树。无论插入、删除、查找都是 O(log n) 的时间复杂度。当然,如果用哈希表来实现集合,插入、删除、查找都可以达到 O(1)。那么为什么集合要用红黑树和没有用哈希表呢?我想,最大的可能是基于集合自身的特性,集合有它特有的操作:求交、求并、求差。这三个操作对于哈希表来说都是 O(n) 的。基于这一点,相比无序的哈希表来说,采用有序的红黑树会更加合适。
二、Redis 整数集合(intset)
今天要讲的整数集合,又称为 intset,是 Redis 特有的数据结构。它的实现既不是红黑树,也不是哈希表。就是简单的数组加上内存编码。当存储元素较少( 元素个数上限定义在server.h 的 OBJ_SET_MAX_INTSET_ENTRIES 宏定义值为512)且均为整型时,才会使用到整数集合。它的查找是 O(log n) 的,插入和删除都是 O(n) 的。但是由于存储元素相对较少的时候,O(log n) 和 O(n) 差距不是很大,但是用 Redis 的这种整数集合,相比红黑树和哈希表来说,可以大大减少内存。
所以,Redis 的 整数集合 intset 的存在主要还是为了节省内存。
1、intset 结构定义
intset 结构定义在 intset.h 中:
#define INTSET_ENC_INT16 (sizeof(int16_t))#define INTSET_ENC_INT32 (sizeof(int32_t))#define INTSET_ENC_INT64 (sizeof(int64_t)) typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset; a) encoding 指定了编码方式,总共有 INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64 三种。从宏定义可以看出,这三个值分别为 2、4、8。从字面意思可以看出三者能表示的范围是 16位整数、32位整数 以及 64位整数。
b) length 存储了整数集合的元素个数。
c) contents 为整数集合的柔性数组,元素类型并不一定是 int8_t 类型的。 contents 不占用结构体的大小,它只作为整数集合数据的首指针。整数集合中的元素按照从小到大的顺序在 contents 中排列起来。
2、编码方式
首先,我们来理解编码方式 encoding 的含义。需要明确的一点是,对于一个整数集合来说,所有的元素的编码一定是一致的(否则每个数都得存一个编码,而不是将它存在 intset 结构体内了),那么整个整数集合的编码取决于集合中“绝对值”最大的那个数(之所以是绝对值,因为整数包含正数和负数)。
通过那个绝对值最大的整数来获取编码,实现如下:
static uint8_t _intsetValueEncoding(int64_t v) { if (v < INT32_MIN || v > INT32_MAX) return INTSET_ENC_INT64; else if (v < INT16_MIN || v > INT16_MAX) return INTSET_ENC_INT32; else return INTSET_ENC_INT16;} 这段代码的含义是,如果整数 v 不能用 32位整数表示,那么就需要用 INTSET_ENC_INT64 编码;如果不能用 16位整数表示,那么就需要用 INTSET_ENC_INT32 编码;否则,采用 INTSET_ENC_INT16 编码就行。核心就是:能用2个字节表示就不用4个字节,能用4个字节表示就不用8个字节,能省则省。
几个宏定义在 stdint.h 中,如下:
# define INT16_MIN (-32767-1) # define INT32_MIN (-2147483647-1) # define INT16_MAX (32767) # define INT32_MAX (2147483647)3、编码升级
当前编码方式不足以存储更大位数的整数时,需要升级编码。举个例子,下图所示的四个数字都在 [ -32768, 32767 ] 范围内,所以采用 INTSET_ENC_INT16 编码即可。contents 的数组长度为 sizeof(int16_t) * 4 = 2 * 4 = 8 个字节 ( 即64个二进制位 )。
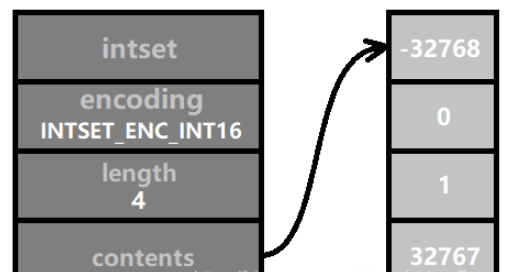
然后我们插入一个数,它的值为 32768,比 INT16_MAX 大1,所以它需要采用 INTSET_ENC_INT32 编码,而整数集合中所有的数的编码需要保持一致。那么,所有数的编码都需要转为 INTSET_ENC_INT32 编码。这就是 “升级”。如图所示:
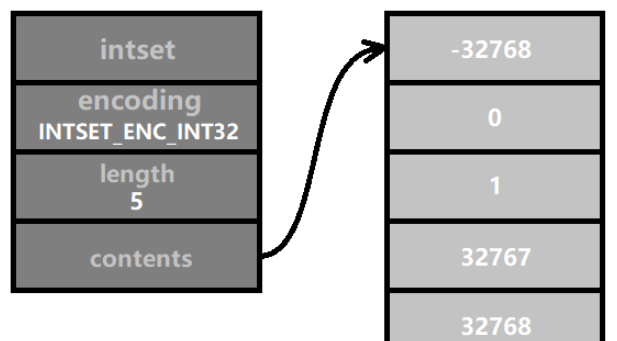
升级完后,contents 数组的长度变为 sizeof(int32_t) * 5 = 4 * 5 = 20 个字节 ( 即160个二进制位 )。而且每个元素占用的内存都扩大一倍,所在的相对位置也发生了变化,导致所有的元素都需要往高位内存迁移。
那我们一开始就把所有的整数集合都用 INTSET_ENC_INT64 来编码不就好了,还省得麻烦。原因是 Redis 设计 intset 的初衷还是为了节省内存,设想一个集合的元素永远都不会超过 16位 整数,那么用 64位整数的话,相当于浪费了 3倍 的内存。
三、整数集合常用操作
1、创建集合
创建一个整数集合 intsetNew,实现在 intset.c 中:
intset *intsetNew(void) { intset *is = zmalloc(sizeof(intset)); is->encoding = intrev32ifbe(INTSET_ENC_INT16); is->length = 0; return is;} 初始创建的整数集合为空集合,用 zmalloc 进行内存分配后,定义编码为 INTSET_ENC_INT16,这样可以使内存尽量小。这里需要注意的是,intset 的存储直接涉及到内存编码,所以需要考虑主机的字节序问题(相关资料请参阅:字节序)。
intrev32ifbe 的意思是 int32 reversal if big endian。即 如果当前主机字节序为大端序,那么将它的内存存储进行翻转操作。简言之,intset 的所有成员存储方式都采用小端序。所以创建一个空的整数集合,内存分布如下:

了解了整数集合的内存编码以后,我们来看看它的 设置 (set)和 获取(get)。
2、元素设置
设置 的含义就是给定整数集合以及一个位置和值,将值设置到这个整数集合的对应位置上。_intsetSet 实现如下:
static void _intsetSet(intset *is, int pos, int64_t value) { uint32_t encoding = intrev32ifbe(is->encoding); if (encoding == INTSET_ENC_INT64) { ((int64_t*)is->contents)[pos] = value; memrev64ifbe(((int64_t*)is->contents)+pos); } else if (encoding == INTSET_ENC_INT32) { ((int32_t*)is->contents)[pos] = value; memrev32ifbe(((int32_t*)is->contents)+pos); } else { ((int16_t*)is->contents)[pos] = value; memrev16ifbe(((int16_t*)is->contents)+pos); }} a) 大端序和小端序只是存储方式,encoding 在存储的时候进行了一次 intrev32ifbe 转换,取出来用的时候需要再进行一次 intrev32ifbe 转换(其实就是序列化和反序列化)。
b) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,然后将 value 的值设置到对应的内存中。
c) memrev64ifbe 的实现参见 字节序 的 memrev64 函数,即将对应内存的值转换成小端序存储。
3、元素获取
获取 的含义就是给定整数集合以及一个位置,返回给定位置的元素的值。_intsetGet 实现如下:
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) { int64_t v64; int32_t v32; int16_t v16; if (enc == INTSET_ENC_INT64) { memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64)); memrev64ifbe(&v64); return v64; } else if (enc == INTSET_ENC_INT32) { memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32)); memrev32ifbe(&v32); return v32; } else { memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16)); memrev16ifbe(&v16); return v16; }} static int64_t _intsetGet(intset *is, int pos) { return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));} a) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,将内存位置上的值拷贝到临时变量中;
b) 由于是直接的内存拷贝,所以取出来的值还是小端序的,那么在大端序的主机上得到的值是不对的,所以需要再做一次 memrev64ifbe 转换将值还原。
4、元素查找
由于整数集合是有序集合,所以查找某个元素是否在整数集合中,Redis 采用的是二分查找。intsetSearch 实现如下:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) { int min = 0, max = intrev32ifbe(is->length)-1, mid = -1; int64_t cur = -1; if (intrev32ifbe(is->length) == 0) { if (pos) *pos = 0; return 0; } else { if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) { if (pos) *pos = intrev32ifbe(is->length); return 0; } else if (value < _intsetGet(is,0)) { if (pos) *pos = 0; return 0; } } while(max >= min) { mid = ((unsigned int)min + (unsigned int)max) >> 1; cur = _intsetGet(is,mid); if (value > cur) { min = mid+1; } else if (value < cur) { max = mid-1; } else { break; } } if (value == cur) { if (pos) *pos = mid; return 1; } else { if (pos) *pos = min; return 0; }} a) 整数集合为空,返回0表示查找失败;
b) value 的值比整数集合中的最大值还大,或者比最小值还小,则返回0表示查找失败;
c) 执行二分查找,将找到的值存在 cur 中;
d) 如果找到则返回1,表示查找成功,并且将 pos 设置为 mid 并返回;如果没找到则返回一个需要插入的位置。
5、内存重分配
由于 contents 的内存是动态分配的,所以每次进行元素插入或者删除的时候,都需要重新分配内存,这个实现放在 intsetResize 中,实现如下:
static intset *intsetResize(intset *is, uint32_t len) { uint32_t size = len*intrev32ifbe(is->encoding); is = zrealloc(is,sizeof(intset)+size); return is;} encoding 本身表示字节个数,所以乘上集合个数 len 就是 contents 数组需要的总字节数了,调用 zrealloc 进行内存重分配,然后返回重新分配后的地址。
注意:zrealloc 的返回值必须返回出去,因为 intset 在进行内存重分配以后,地址可能就变了。即 is = zrealloc(is, ...) 中,此 is 非彼 is。所以,所有调用 intsetResize 的函数都需要连带的返回新的 intset 指针。
6、编码升级
编码升级一定发生在元素插入,并且插入的元素的绝对值比整数集合中的元素都大的时候,所以我们把升级后的元素插入和编码升级放在一个函数实现,名曰 intsetUpgradeAndAdd,实现如下:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) { uint8_t curenc = intrev32ifbe(is->encoding); uint8_t newenc = _intsetValueEncoding(value); int length = intrev32ifbe(is->length); int prepend = value < 0 ? 1 : 0; is->encoding = intrev32ifbe(newenc); is = intsetResize(is,intrev32ifbe(is->length)+1); while(length--) _intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); if (prepend) _intsetSet(is,0,value); else _intsetSet(is,intrev32ifbe(is->length),value); is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is;} a) curenc 记录升级前的编码,newenc 记录升级后的编码;
b) 将整数集合 is 的编码设置成新的编码后,进行内存重分配;
c) 获取原先内存中的数据,设置到新内存中(注意:由于两段内存空间是重叠的,而且新内存的长度一定大于原先内存,所以需要从后往前进行拷贝);
d) 当插入的值 value 为负数的时候,为了保证集合的有序性,需要插入到 contents 的头部;反之,插入到尾部;当 value 为负数时 prepend 为1,这样就可以保证在内存拷贝的时候将第 0 个位置留空。
如图展示了一个 (-32768, 0, 1, 32767) 的整数集合在插入数字 32768 后的升级的完整过程:

整数集合升级的时间复杂度是 O(n) 的,但是在整数集合的生命期内,升级最多发生两次(从 INTSET_ENC_INT16 到 INTSET_ENC_INT32 以及 从 INTSET_ENC_INT32 到 INTSET_ENC_INT64)。
7、内存迁移
绝大多数情况都是在执行 插入 、删除 、查找 操作。插入 和 删除 会涉及到连续内存的移动。Redis 的内部实现中有一个函数 intsetMoveTail 就是用来实现内存移动的。
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) { void *src, *dst; uint32_t bytes = intrev32ifbe(is->length)-from; uint32_t encoding = intrev32ifbe(is->encoding); if (encoding == INTSET_ENC_INT64) { src = (int64_t*)is->contents+from; dst = (int64_t*)is->contents+to; bytes *= sizeof(int64_t); } else if (encoding == INTSET_ENC_INT32) { src = (int32_t*)is->contents+from; dst = (int32_t*)is->contents+to; bytes *= sizeof(int32_t); } else { src = (int16_t*)is->contents+from; dst = (int16_t*)is->contents+to; bytes *= sizeof(int16_t); } memmove(dst,src,bytes); } a) 统计从 from 到结尾,有多少个元素;
b) 根据不同的编码,计算出需要拷贝的内存字节数 bytes,以及拷贝源位置 src,拷贝目标位置 dst;
c) memmove 是 string.h 中的函数:src指向的内存区域拷贝 bytes 个字节到 dst 所指向的内存区域,这个函数是支持内存重叠的;
8、元素插入
最后,讲整数集合的插入和删除,插入调用的是 intsetAdd,在 intset.c 中实现:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) { uint8_t valenc = _intsetValueEncoding(value); uint32_t pos; if (success) *success = 1; if (valenc > intrev32ifbe(is->encoding)) { return intsetUpgradeAndAdd(is,value); } else { if (intsetSearch(is,value,&pos)) { if (success) *success = 0; return is; } is = intsetResize(is,intrev32ifbe(is->length)+1); if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); } _intsetSet(is,pos,value); is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is;} a) 插入的数值 value 的内存编码大于现有集合的编码,直接调用 intsetUpgradeAndAdd 进行编码升级;
b) 集合元素是不重复的,如果 intsetSearch 能够找到,则将 success 置为0,表示此次插入失败;
c) 如果 intsetSearch 找不到,将 intset 进行内存重分配,即 长度 加 1。
d) pos 为 intsetSearch 过程中找到的 value 将要插入的位置,我们将 pos 以后的内存向后移动1个单位 (这里的1个单位可能是2个字节、4个字节或者8个字节,取决于当前整数集合的内存编码)。
e) 调用 _intsetSet 将 value 的值设置到 pos 的位置上,然后给成员变量 length 加 1。最后返回 intset 指针首地址,因为其间进行了 intsetResize,传入的 intset 指针和返回的有可能不是同一个了。
9、元素删除
删除元素调用的是 intsetRemove ,实现如下:
intset *intsetRemove(intset *is, int64_t value, int *success) { uint8_t valenc = _intsetValueEncoding(value); uint32_t pos; if (success) *success = 0; if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) { uint32_t len = intrev32ifbe(is->length); if (success) *success = 1; if (pos < (len-1)) intsetMoveTail(is,pos+1,pos); is = intsetResize(is,len-1); is->length = intrev32ifbe(len-1); } return is;} a) 当整数集合中存在 value 这个元素时才能执行删除操作;
b) 如果能通过 intsetSearch 找到元素,那么它的位置就在 pos 上,这是通过 intsetMoveTail 将内存往前挪;
c) intsetResize 重新分配内存,并且将集合长度减1;
感谢各位的阅读,以上就是“Redis整数集合的使用方法有哪些”的内容了,经过本文的学习后,相信大家对Redis整数集合的使用方法有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!













