
【51CTO.com快译】如果管理者计划在组织内部或项目中采用SRE文化,那么需要了解如何更好地培训其SRE团队并遵循优秀实践。
什么是站点可靠性工程(SRE)?
站点可靠性工程(SRE)这一概念起源于谷歌公司,SRE是一种IT运营方法,与DevOps密切相关。SRE团队使用该软件来管理系统、解决问题和自动化操作任务。
SRE团队承担IT运营团队完成的人工任务,并将其交给使用工具和自动化解决问题和管理生产系统的工程师或运营团队。
在创建可扩展且高度可靠的软件系统时,这是一种更具价值的实践。SRE团队通过代码帮助组织管理庞大的基础设施,这对于管理大量机器的系统管理员来说更具可扩展性和可持续性。
为什么SRE很重要?如何构建优秀的SRE团队?
SRE就像是沟通软件工程团队和IT运营团队之间的桥梁,填补了两者之间的空白。几乎在任何地方,SRE随时随地都在为生产系统中的故障做好准备时发挥作用。它确保组织的系统具有可扩展性、可靠性、可预测性和自动化。
SRE还设置了服务水平指标(SLI)、服务水平目标(SLO)、服务水平协议(SLA) ,其中定义了性能的真实数字、团队满足该协议必须达到的目标,以及系统对最终用户的可靠性要求。SRE的主要目标是提高性能和运营效率。
因此,SRE人员不仅仅是“编写代码的运营人员”,也应该是开发团队的成员,并且拥有不同的技能,尤其是在部署、配置管理、监控、指标等方面。SRE团队需要负责这些领域,正如开发工程师必须知道如何从数据存储中提取数据一样。而SRE团队需要通力合作,交付易于更新、管理和监控的产品。当企业正在实现DevOps项目,但意识到他们对开发人员的要求太高,并且需要专家来处理运营团队过去处理的事情时,就自然会产生对SRE人员的需求。
在了解SRE以及SRE团队如何与开发团队合作之前,需要了解SRE如何在DevOps模式中发挥作用。
SRE团队如何与DevOps团队协同工作?
从本质上来说,SRE是DevOps模式的实现。正如持续集成和持续交付是DevOps原则在软件发布中的应用程序一样,SRE是这些原则在软件可靠性中的应用。
定义DevOps的方法有很多种。尽管如此,传统模式是将开发(“Dev”)团队和运营(“Ops”)团队分开,这导致编写代码的团队在客户开始使用代码时不负责代码的工作方式,而会将这些代码直接交给运维团队安装和支持。
根据谷歌公司的方法,组织可以使用SRE在其内部更好地采用DevOps原则并衡量实施是否成功。
为了更好将这两者结合起来,需要考虑以下原则:
- 减少组织孤岛:SRE通过在开发人员和运营团队之间共享所有权来提供帮助。这是DevOps的主要原则之一。当SRE团队专注于改进问题检测和应用程序性能时,运营人员可以专注于管理基础设施,而开发人员可以专注于功能改进。
- 接受失败:与DevOps团队一样,SRE团队不会将故障和生产事件的责任推给IT团队。无责任事后分析是一种SRE优秀实践,可以确保所有事件都被作为一种学习机会。当接受失败正常化时,团队可以承担更大的风险,从而有可能带来更大的创新,而不必担心过多的挫折或阻碍。
- 实施渐进式变革:与DevOps团队一样,SRE团队也鼓励通过变革进行持续改进。SRE要求小而频繁的更改。因此,任何负面影响的影响都会很小,并且可以轻松测试和实施低风险的增强功能。
- 利用工具和自动化:虽然DevOps团队鼓励自动化和技术采用,但SRE团队专注于在IT团队中采用一致的技术和信息访问。这样可以更轻松地管理和运营,并减少因技术不兼容而产生问题的机会。这种标准化还有助于确保团队的成员可以更好地协作,因为工具是统一的,并且不太可能需要一些成员不具备的专业技能。
- 衡量一切:SRE将指标与反馈循环相结合,以衡量运营并确定改进机会。它还根据需要为风险和人工操作建立冗余性,使其通过衡量更具可预测性。通过应用指标数据,团队可以设定适当的目标,同时保持合理的绩效预期。
现在知道SRE很重要的原因,以下继续讨论在接受SRE文化时必须遵循的SRE优秀实践。
SRE的优秀实践
在实施SRE时,组织可能需要一些时间来完善其策略并定制实践以满足运营需求。为了帮助加快这一过程,需要考虑以下SRE原则和优秀实践。
(1)错误预算
简而言之,错误预算是在用户开始不满意之前,组织的服务在一段时间内可以累积的错误量。可以将其视为用户的痛苦容忍度,但适用于服务的可用性和延迟等特定维度。为了计算误差预算,必须使用SLI方程:
SLI=[良好事件/有效事件]×100
在这个公式中的百分比表示为SLI,一旦组织为每个SLI定义了一个目标,这就是其服务水平目标(SLO),而错误预算就是剩余部分,最高可以达到100。
例如,假设组织正在衡量网站主页的可用性。可用性是通过响应错误的请求数除以主页收到的所有有效请求数量来衡量的(以百分比)表示。如果决定该可用性的目标是99.9%,则错误预算为0.1%。组织最多可以出现0.1%的错误(最好略低于0.1%),用户会很乐意继续使用该服务。
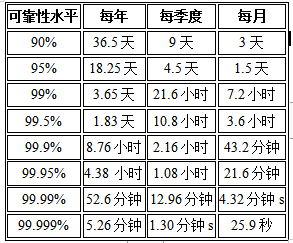
以下这个表格表明百分比如何转换为出现错误的时间:
乍一看,错误预算似乎并不那么重要。它们只是IT团队和DevOps团队需要跟踪以确保一切顺利运行的一个指标。这种说法是错误的。错误预算不仅仅是确保组织履行合同承诺的便捷方式。如果团队用尽了某一季度的错误预算,则新的预算通常会被冻结。它们也是开发团队创新和冒险的机会。
(2)像用户一样定义服务水平目标(SLO)
服务水平目标(SLO)用来衡量对最终用户很重要的可用性和性能。SLO是所有SRE的基础,而没有SLO,组织就无法制定错误预算、确定开发工作的优先级或进行及时有效的事件管理。SLO应该指定它们的衡量方式以及有效的条件。
①服务水平指标(SLI):
对所提供服务水平的某些方面(例如吞吐量、延迟)进行的定量度量。通过SLI:
- 用户可以直接测量和观察。
- 可以代表用户的体验,简单来说就是了解用户到底要衡量什么。
②服务水平目标(SLO):
SLI测量的服务级别的目标值或值范围。通过SLO:
- 从用户的角度定义服务应该如何执行(通过SLI衡量)。简单来说,提供服务应该有多好,以及需要改进服务的阈值。
- 是用户可以考虑打开支持票证的时间点。
- 受业务需求驱动,而不仅仅是当前性能。
③服务水平协议(SLA):
如果服务未达到预期,则向客户提供某种形式的补偿的商业合同。简单来说,SLA 就是SLO+后果。
(3)监控错误和可用性
为了识别性能错误并保持服务可用性,SRE团队需要了解他们的系统中发生了什么。需要监控以验证应用程序/系统是否按预期运行,这意味着服务、满足特定目标以及了解更改时会发生什么。而且要在客户之前知道这些。
(4)高效规划能力
组织需要为业务的有机增长(可能是产品采用率的增加)和无机增长(由于功能发布、营销活动等导致需求的突然增长)等进行规划。这些活动将消耗更多资源(如黑色星期五导致的停机)。为准备这些活动,组织需要预测需求并规划采购时间。
容量规划的重要方面包括定期负载测试和资源调配。定期负载测试可让组织了解系统在日常用户的平均压力下如何运行。此外,以任何形式增加容量都可能成本昂贵,因此组织了解在何处需要额外资源是关键。
(5)注重变革管理
在许多组织中,大多数停机都是由对活动系统的更改引起的,无论是新的二进制推送还是新的配置推送。每一个微小的变化都会影响业务。因此,需要分析每个变更所带来的风险,并且应该受到监督。组织需要通过查看大局来考虑长期变化的影响,而不仅仅是它们如何影响当今的系统。
为确保在变更期间不会发生任何意外,必须由执行推出阶段的工程师或最好是一个可证明可靠的监控系统对其进行监控。如果检测到意外行为,首先进行回滚,然后进行诊断,以最大限度地缩短平均恢复时间 (MTTR)。
(6)无责任的事后分析
无责任的事后分析有助于在组织中建立更可靠的系统。事后分析应该是无可指责的,并且应该关注流程和技术,而不是人员的责任。
假设事件中涉及的人员根据他们当时可用的信息做出最好的选择。将事件归咎于某人或某个团队会适得其反。因为这将会带来人们不敢冒险、不敢创新、不敢解决问题的氛围和环境。
失败总是会发生的,这是没有办法的事情。但是,通过良好的事件解决方案和回顾性实践,经历失败也可能是有益的。它揭示了需要关注的领域以提高弹性。只要人们从事件中吸取教训,就会取得进步。
(7)劳动管理
SRE的主要关注点之一是自动化。一些重复性劳动对于开发人员来说是一种时间的浪费,通过SRE创建框架、流程、内部工具/构建工具来消除这些重复性劳动,将会让工程师专注于技术创新。
结论
本文试图涵盖建立成功的SRE团队所需的基本概念和实践。如果管理者计划在项目和组织内部采用 SRE文化,需要培训团队、遵循优秀实践并信任该过程。虽然不可能达到 100% 的完美,但是会让事情变得更加精简并尽可能接近完美。
原文Site Reliability Engineering (SRE) Best Practices,作者:Rayan Das
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】












{kind=link}