
这篇文章主要为大家展示了“React中调和算法Diffing算法策略的示例分析”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“React中调和算法Diffing算法策略的示例分析”这篇文章吧。
算法策略
React的调和算法,主要发生在render阶段,调和算法并不是一个特定的算法函数,而是指在调和过程中,为提高构建workInProcess树的性能,以及Dom树更新的性能,而采用的一种策略,又称diffing算法。 在React 的官网上描述“Diffing” 算法时,提到了“diffing two trees”,但是在源码实现时,并不是创建好两棵树后,再从上往下的diffing这两棵树。这个diffing发生在搭建子节点时, 实际是新生成的ReactElement 与 current树上fibe节点的diffing。 为了将diffing算法的时间复杂度控制在O(n)(树diff的时间复杂度涉及到树的编辑距离,可以看这里), 采用了如下策略:
只比较同层级的节点,(貌似这一点没有在官网中提到)
对于单节点比较,如果当前节点type 和 key 不相同,不再比较其下子节点,直接删掉该节点及其下整棵子树,根据ReactElement重新生成节点树。因为React认为不同类型的组件生成的树形结构不一样,不必复用。
如果子节点是数组,可根据唯一的key值定位节点进行比较,这样即使子节点顺序发生变化,也可以根据key值进行复用。
值得注意的是,所有节点的diffing都会比较key,key 默认值为null。若是没有设置,则null是恒等于null的,认为key是相同的。
单节点diffing
单个节点进行diffing时,会diffing两组属性:fibe.elementType vs ReactElement.type , fibe.key vs ReactElement.key, 如果这两组属性都相等,数据结构的物理空间会有如下复用逻辑(详见源码reconcileSingleElement函数):
如果current fibe 存在 alternate 节点,(这意味着这个fibe节点之前参与过调和),则复用该alternate节点的物理空间;否则需要clone current fibe节点,占用新的物理空间
对应的instance 或者 Dom 会被复用
current fibe 下的child树也会被直接挂载过来(下一步递归子节点时,会被使用)
如果两组属性有一个不相等:
fibe 根据ReactElement重新创建
对应的instance和Dom 也会重建
child 树全部删除。
如果生成的ReactElement 是单节点,但是对应的current树上是多节点时,会从逐一查找有没有匹配的,找到匹配的,其他的都删除;找不到,全部删除。例如Couter组件有如下逻辑:当点击次数大于10时,隐藏点击按钮。当到达第10次时,span节点会被复用。
class Counter extends React.Component{ state={ count:0 } addCount = ()=>{ const count = this.state.count+1; this.setState({count}) } componentDidUpdate(){ console.log("updated") } render(){ return this.state.count < 10 ? [ <button onClick={this.addCount}>点击</button> <span>点击次数:{this.state.count}</span> ]:<span>点击次数:{this.state.count}</span>; }}数组节点diffing
数组节点进行diffing时,流程比较复杂:(源码见reconcileChildrenArray函数)
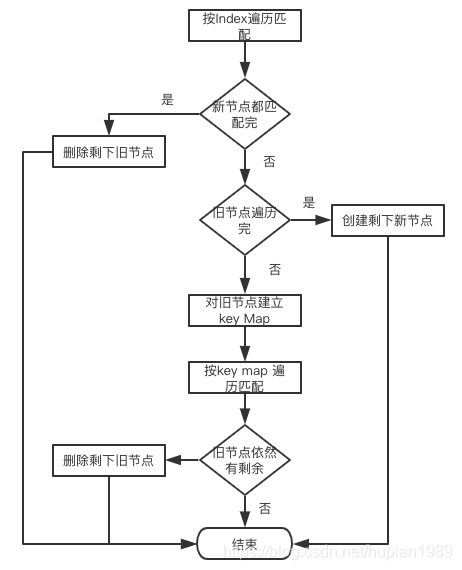
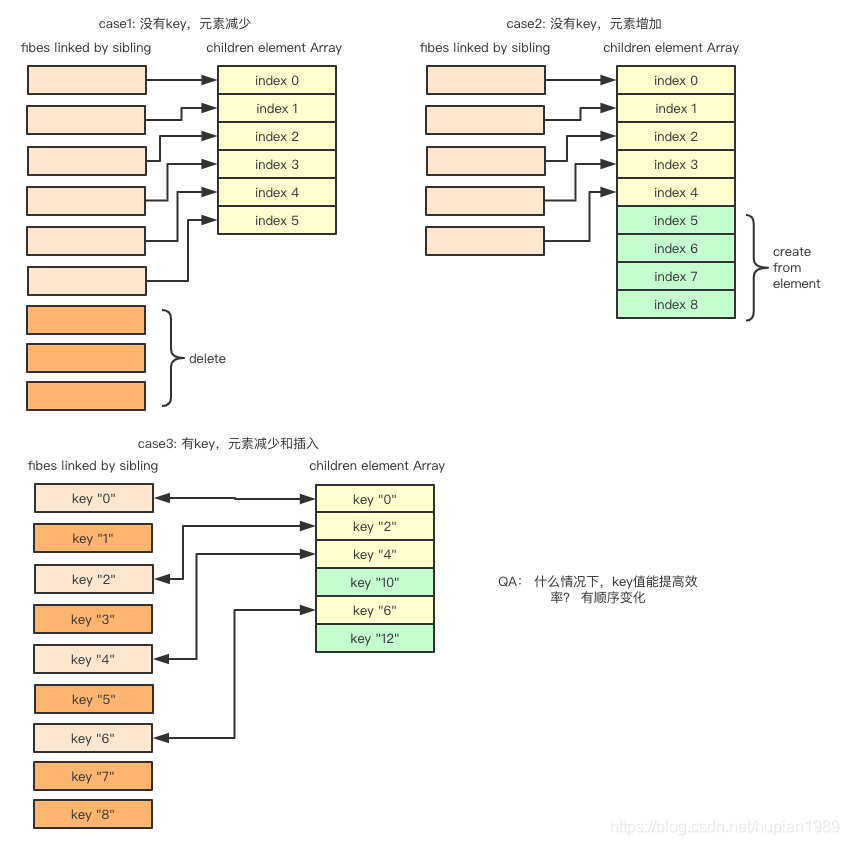
中间有两次重要的遍历,第一次按index遍历,新旧节点依次比较,遇到key值不匹配的立即中断遍历。 第二次遍历,对剩下的旧节点建立 “key - 节点”的Map表,遍历剩下的新节点,按key值从表中查找旧节点进行比较。以下是三种case下,新旧节点匹配比较的情况。
key值的使用要求
从单节点和数组节点的diffing上看,key值主要是为了减少新建。为了保证diffing时新建旧节点能匹配上,key值使用时有如下注意:
得稳定,如果key值每次都变化(比如使用了随机数),diffing时,新旧节全部匹配不上,将会引起大量的新建;
必须得唯一,如果key值不唯一,在建立“key - 节点”的Map表时,会遗漏和错乱,导致页面更新错误。
对于单节点,diffing时key值也会用到,不要认为其没用随便乱设置。 也有一些不规范的用法,对单节点使用key值来实现组件的销毁和重建,但这种用法是不符合React的设计理念的。
例如,有一个日志组件,内部拉取日志数据,对外部没有数据依赖。但是在需求迭代时,在同页面增加了审批操作,审批后,后端会新增一条日志数据,这时候会希望前端页面实时的展示新增的日志数据,会需要触发日志组件重新拉取数据。如果不使用向上提升数据的方式来解决问题,可以给该组件指定一个随机的key,当审批操作完成时,修改key值,则组件就会重新构建。但这种方式的开销较高,整个组件树都会销毁重建。可以采用其他解决方案代替,例如可以给该组件指定ref,当审批完成后,通过ref调用该组件的刷新函数,重新获取数据,更新组件。
对于数组节点,key值主要是在子节点位置发生大的错位时,会起到关键作用。 对于普通的末尾新增,和末尾删除,第一次index遍历就可以匹配完,不会进入第二次key map的遍历。 因为key值对“稳定”和“唯一”性这两个要求,一般前端会需要后端对list数据提供一个唯一标识,对于聚合接口,会给后端增加额外工作,这种情况,可以先了解数据的变化特性,再决定是否真的需要设置key。
对于上面的日志组件,日志是一个列表,新增的日志,都是插在第一行,如果不设置key,基本上所有的子节点都要更新。如果设置key,就需要后端服务为每一条日志增加“永远”惟一的标识符,例如id。曾经经历过一次因为key值的唯一性变化,导致数据更新时页面展示错误的案例。
以上是“React中调和算法Diffing算法策略的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注编程网行业资讯频道!







