
一、文件的编码
思考:计算机只能识别:0和1,那么我们丰富的文本文件是如何被计算机识别,并存储在硬盘中呢?
答案:使用编码技术( 密码本)将内容翻译成0和1存入
编码技术即:翻译的规则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容
为什么需要使用编码?
计算机只认识0和1,所以需要将内容翻译成0和1才能保存在计算机中。同时也需要编码,将计算机保存的0和1,反向翻译回可以识别的内容
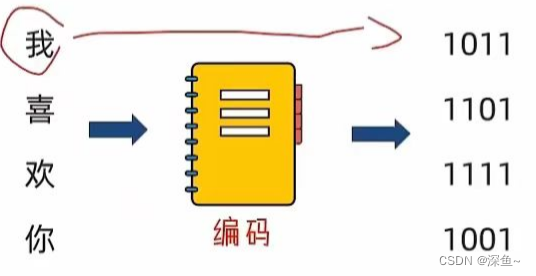
计算机中有许多可用编码
·UTF-8(UTF-8是目前全球通用的编码格式除非有特殊需求,否则,一律以UTF-8格式进行文件编码即可)
·GBK
·Big5
·等
不同的编码,将内容翻译成二进制也不同的,所以要使用正确的编码,才能对文件进行正确的读写操作

如上,如果你给喜欢的女孩发送文件,使用编码A进行编码(内容转二进制)。
女孩使用编码B打开文件进行解码 (二进制反转回内容)
自求多福吧
二、文件的读取
0.文件操作的概述
想想我们平常对文件的基本操作,大概可以分为三个步骤(简称文件操作三步走):
(1)打开文件
(2)读写文件
(3) 关闭文件
注意:可以只打开和关闭文件,不进行任何读写
1.open()打开函数
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下
open(name, mode, encoding)
name: 是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode: 设置打开文件的模式(访问模式): 只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
示例代码:
f=open('python.txt'r'encoding=”UTF-8) # encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定注意:此时的“f”是 ope 函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问
2.mode常用的三种基础访问模式
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除,如果该文件不存在,创建新文件 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后 如果该文件不存在,创建新文件进行写入 |
3.读操作相关方法
(1) read( )方法:
f = open("C:/Users/test_10_19/测试.txt", "r", encoding="UTF-8")print(f"读取10个字节的结果:{f.read(10)}")print(f"read方法读取全部内容的结果是:{f.read()}")f.close()文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
(2) readlines( )方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
f = open("C:/Users/test_10_19/测试.txt", "r", encoding="UTF-8")lines = f.readlines()print(f"lines对象的类型:{type(lines)}")print(f"lines对象的内容是:{lines}")f.close()注意:如果文件不止一行,那么列表的元素最后都会有\n(最后一行不一定)
(3) readline()方法:一次读取一行内容
f = open("C:/Users/test_10_19/测试.txt", "r", encoding="UTF-8")line1 = f.readline()line2 = f.readline()line3 = f.readline()print(f"第一行数据是:{line1}")print(f"第二行数据是:{line2}")print(f"第三行数据是:{line3}")f.close()(4) for循环读取文件行
for line in f: print(f"每一行的数据是:{line}")# 每一个line临时变量,就记录了文件的一行数据close( )关闭文件对象
f = open("C:/Users/test_10_19/测试.txt", "r", encoding="UTF-8")f.close()#最后通过close,关闭文件对象,也就是关闭对文件的占用
#如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用
with open 语法
with open("C:/Users/test_10_19/测试.txt", "r", encoding="UTF-8") as f: for line in f: print(f"每一行数据是:{line}")#通过在with open的语句块中对文件进行操作
#可以在操作完成后自动关闭close文件,避免遗忘掉close方法
总结:
| 操作 | 功能 |
| 文件对象=open(file,mode,encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for linein 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
三、文件的写入
f = open("C:/Users/test_10_19/测试.txt", "w", encoding="UTF-8")# write写入f.write("Hello World!") # 内容写入到内存中# flush刷新f.flush() # 将内存中积攒的内存,写入到硬盘的文件中# close关闭f.close() # close方法,内置了flush的功能 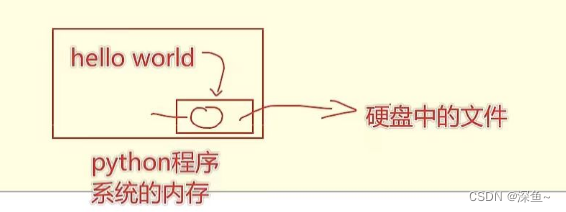
因为close方法,内置了flush的功能 ,所以flush刷新可以不写
注意:
·直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,-称之为缓冲区
·当调用flush的时候,内容会真正写入文件0
·这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
四、文件的追加
f = open("C:/Users/test_10_19/测试.txt", "a", encoding="UTF-8")# write写入f.write("Hello World!") # 内容写入到内存中# flush刷新f.flush() # 将内存中积攒的内存,写入到硬盘的文件中# close关闭f.close() # close方法,内置了flush的功能 注意:
·a模式,文件不存在会创建文件
·a模式,文件存在会在最后,追加写入文件
本次内容就到此啦,欢迎评论区或者私信交流,觉得笔者写的还可以,或者自己有些许收获的,麻烦铁汁们动动小手,给俺来个一键三连,万分感谢 !

来源地址:https://blog.csdn.net/qq_73017178/article/details/133933328







