
本篇内容介绍了“Spark SQL配置及使用的方法是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
XY个人记
SparkSQL是spark的一个模块,主入口是SparkSession,将SQL查询与Spark程序无缝混合。DataFrames和SQL提供了访问各种数据源(通过JDBC或ODBC连接)的常用方法包括Hive,Avro,Parquet,ORC,JSON和JDBC。您甚至可以跨这些来源加入数据。以相同方式连接到任何数据源。Spark SQL还支持HiveQL语法以及Hive SerDes和UDF,允许您访问现有的Hive仓库。
Spark SQL包括基于成本的优化器,列式存储和代码生成,以快速进行查询。同时,它使用Spark引擎扩展到数千个节点和多小时查询,该引擎提供完整的中间查询容错。不要担心使用不同的引擎来获取历史数据。
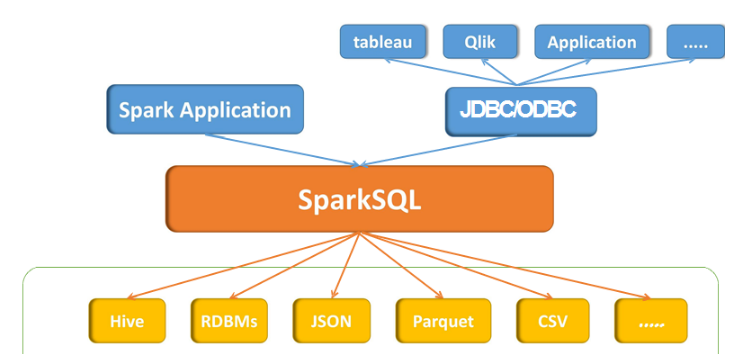
SparkSQL版本:
Spark2.0之前
入口:SQLContext和HiveContext
SQLContext:主要DataFrame的构建以及DataFrame的执行,SQLContext指的是spark中SQL模块的程序入口
HiveContext:是SQLContext的子类,专门用于与Hive的集成,比如读取Hive的元数据,数据存储到Hive表、Hive的窗口分析函数等
Spark2.0之后
入口:SparkSession(spark应用程序的一个整体入口),合并了SQLContext和HiveContext
SparkSQL核心抽象:DataFrame/Dataset type DataFrame = Dataset[Row] //type 给某个数据类型起个别名
SparkSQL DSL语法
SparkSQL除了支持直接的HQL语句的查询外,还支持通过DSL语句/API进行数 据的操作,主要DataFrame API列表如下:
select:类似于HQL语句中的select,获取需要的字段信息
where/filter:类似HQL语句中的where语句,根据给定条件过滤数据
sort/orderBy: 全局数据排序功能,类似Hive中的order by语句,按照给定字段进行全部 数据的排序
sortWithinPartitions:类似Hive的sort by语句,按照分区进行数据排序
groupBy:数据聚合操作
limit:获取前N条数据记录
SparkSQL和Hive的集成
集成步骤:
-1. namenode和datanode启动
-2. 将hive配置文件软连接或者复制到spark的conf目录下面
$ ln -s /opt/modules/apache/hive-1.2.1/conf/hive-site.xml or$ cp /opt/modules/apache/hive-1.2.1/conf/hive-site.xml ./ -3. 根据hive-site.xml中不同配置项,采用不同策略操作
根据hive.metastore.uris参数
-a. 当hive.metastore.uris参数为空的时候(默认值)
将Hive元数据库的驱动jar文件添加spark的classpath环境变量中即可完成SparkSQL到hive的集成
-b. 当hive.metastore.uris非空时候
-1. 启动hive的metastore服务
./bin/hive --service metastore &
-2. 完成SparkSQL与Hive集成工作
-4.启动spark-SQL($ bin/spark-sql)时候 发现报错:
java.lang.ClassNotFoundException: org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.util.Utils$.classForName(Utils.scala:228)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:693)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:185)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:210)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:124)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Failed to load main class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.
You need to build Spark with -Phive and -Phive-thriftserver.
解决办法:将spark源码中sql/hive-thriftserver/target/spark-hive-thriftserver_2.11-2.0.2.jar拷贝到spark的jars目录下
完成。(查看数据库 spark-sql (default)> show databases; ,它操作的都是Hive)
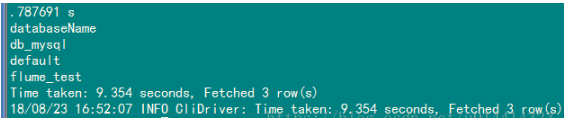
编写两个简单的SQL
spark-sql (default)> select * from emp;
也可以做两张变的jion
spark-sql (default)> select a.*,b.* from emp a left join dept b on a.deptno = b.deptno;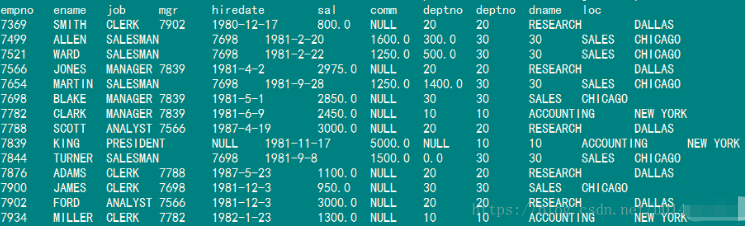
可以对表进行一个缓存操作3
> cache table emp; #缓存操作> uncache table dept; #清除缓存操作> explain select * from emp; #执行计划我们可以看到相应的Storage信息,执行完清除缓存操作后下面的Stages操作消失


启动一个Spark Shell,可以直接在shell里面编写SQL语句
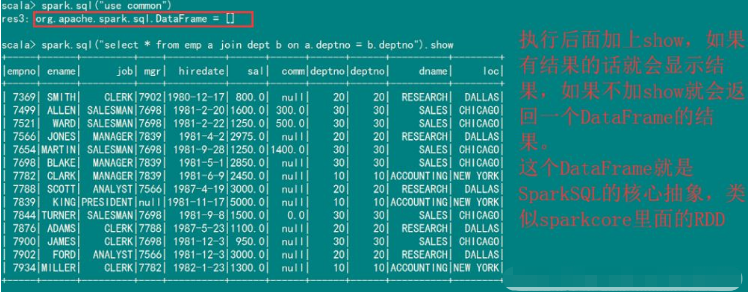
$ bin/spark-shell#可以在shell里面写sqlscala> spark.sql("show databases").showscala> spark.sql("use common").showscala> spark.sql("select * from emp a join dept b on a.deptno = b.deptno").show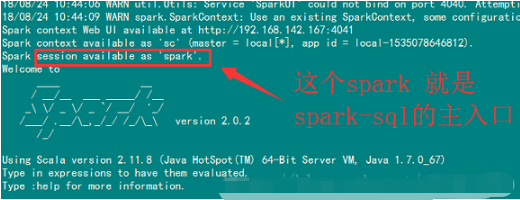
用一个变量名称接收DataFrame
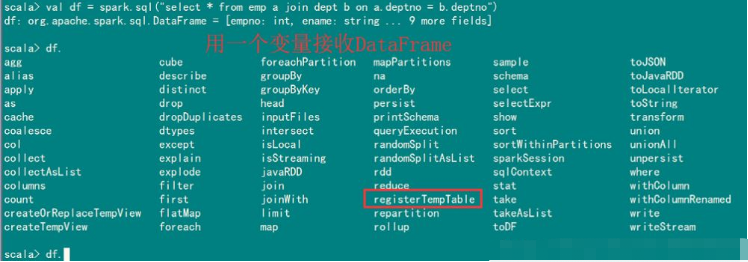
比如使用registerTempTable注册一个临时表。注:临时表是所有数据库公有的不需要指定数据库
scala> df.registerTempTable("table_regis01")
Spark应用依赖第三方jar包文件解决方案
在我们的4040页面Environment节点下的Classpath Entries节点里可以看到我们服务所依赖的jar包。http://hadoop01.com:4040/environment/
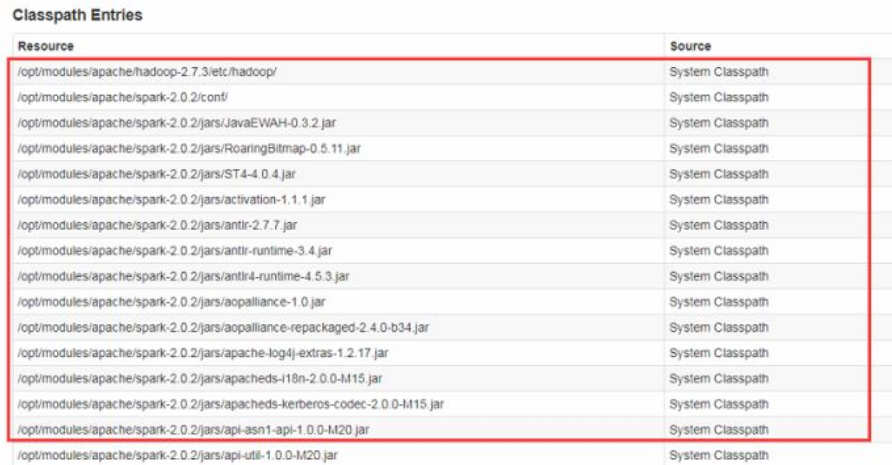
1.直接添加驱动jar到${SPARK_HOME}/jars
2. 使用参数--jars 添加本地jar包
./bin/spark-shell --jars jars/mysql-connector-java-5.1.27-bin.jar,/opt/modules/hive-1.2.1/lib/servlet-api-2.5.jar
添加多个本地jar的话,用逗号隔开
./bin/spark-shell --jars jars/mysql-connector-java-5.1.27-bin.jar,/opt/modules/hive-1.2.1/lib // 方法二 spark .read .table("tmp_emp_join_dept_result") .write .format("parquet") .save(s"hdfs://hadoop01.com:8020/spark/sql/hive_join_mysql/${System.currentTimeMillis()}") //输出到Hive中,并且是parquet格式 按照deptno分区 spark .read .table("tmp_emp_join_dept_result") .write .format("parquet") .partitionBy("deptno") .mode(SaveMode.Overwrite) .saveAsTable("hive_emp_dept") println("------------------------------------------------------------") spark.sql("show tables").show() //清空缓存 spark.catalog.uncacheTable("tmp_emp_join_dept_result") }}
可以打成jar文件放在集群上执行
bin/spark-submit \--class com.jeffrey.sql.HiveJoinMySQLDemo \--master yarn \--deploy-mode client \/opt/datas/jar/hivejoinmysql.jar bin/spark-submit \--class com.jeffrey.sql.HiveJoinMySQLDemo \--master yarn \--deploy-mode cluster \/opt/datas/logAnalyze.jar以上即使Spark SQL的基本使用。
SparkSQL的函数
HIve支持的函数,SparkSQL基本都是支持的,SparkSQL支持两种自定义函数,分别是:UDF和UDAF,两种函数都是通过SparkSession的udf属性进行函数的注册使用的;SparkSQL不支持UDTF函数的 自定义使用。
☆ UDF:一条数据输入,一条数据输出,一对一的函数,即普通函数
☆ UDAF:多条数据输入,一条数据输出,多对一的函数,即聚合函数
“Spark SQL配置及使用的方法是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!















