
无论是做研究还是实际工作,都需要经过长期的积累,才能深刻理解存在的问题、解决方法、瓶颈所在、突破方向等等。
今天和大家聊一下压缩算法相关的知识点,废话不说,马上开始阅读之旅吧!
2.压缩算法的理论基础
任何适用于工程的算法都有它的数学和信息学理论基础。
就如同我们写论文要先做仿真,理论给实践提供了一定的方向和依据。
对于压缩算法来说,我们肯定会问:这是压缩极限了吗?还有提升空间吗?
2.1 信息学之父
聊到这里,不得不提到信息学之父克劳德·艾尔伍德·香农,来简单看下他的履历简介:
克劳德·艾尔伍德·香农(Claude Elwood Shannon ,1916年4月30日—2001年2月24日)是美国数学家、信息论的创始人。
1936年获得密歇根大学学士学位,1940年在麻省理工学院获得硕士和博士学位,1941年进入贝尔实验室工作,1956年他成为麻省理工学院客座教授,并于1958年成为终生教授,1978年成为名誉教授。
香农提出了信息熵的概念,为信息论和数字通信奠定了基础,他也是一位著名的密码破译者。他在贝尔实验室破译团队主要追踪德国飞机和火箭。
相关论文:1938年的硕士论文《继电器与开关电路的符号分析》,1948年的《通讯的数学原理》和1949年的《噪声下的通信》,1949年的另外一篇重要论文《Communication Theory of Secrecy Systems》。
看完这段介绍,我感觉自己被秒成了粉末了,只能默默打开了网抑云,生而为人,我很遗憾。
2.3 信息熵entropy
熵本身是一个热力学范畴的概念,描述了一种混乱程度和无序性。
这是个特别有用的概念,因为自然界的本质就是无序和混乱。
举个不恰当的例子,我们经常看娱乐圈八卦新闻的时候,会说信息量很大,上热搜了等等,那么我们该如何去度量信息量呢?
前面提到的信息学之父香农就解决了信息的度量问题,让一种无序不确定的状态有了数学语言的描述。
在1948年的论文《A Mathematical Theory of Communication》中作者将Entropy与Uncertainty等价使用的。
文中提出了信息熵是信息的不确定性(Uncertainty)的度量,不确定性越大,信息熵越大。
论文地址:http://people.math.harvard.edu/~ctm/home/text/others/shannon/entropy/entropy.pdf
在论文的第6章给出信息熵的几个属性以及信息熵和不确定性之间的联系:
简单翻译一下:
- 信息熵是随着概率连续变化的;
- 如果构成事件的各个因素的概率相等,那么信息熵随构成因素总数n的增加而增加,即选择越多,不确定性越大。
- 当一个选择可以分解为两个连续选择时,分解前后的熵值应该相等,不确定性相同。
我们假设一个事件有多种可能的选择,每个选择的概率分别记为p1,p2....pn,文章进一步给出了概率和信息熵的公式:
其中k为一个正常量。
经过前面的一些分析,我们基本上快懵圈了,太难了。
所以,我们暂且记住一个结论:信息是可度量的,并且和概率分布有直接联系。
3. 数据压缩的本质
既然有了理论的支持,那么我们来想一想 如何进行数据压缩呢?
数据压缩可以分为:无损压缩和有损压缩。
无损压缩 适用于必须完整还原原始信息的场合,例如文本、可执行文件、源代码等。
有损压缩,压缩比很高但无法完整还原原始信息,主要应用于视频、音频等数据的压缩。
3.1 数据压缩的定义
压缩的前提是冗余的存在,消除冗余就是压缩,用更少的信息来完整表达信息,来看下百科的定义:
数据压缩是指在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率,
需要按照一定的算法对数据进行重新组织,减少数据的冗余和存储的空间的一种技术方法。
举几个简单的例子:
- "北京交通大学的交通信息工程及控制专业不错" 和 "北交的交控专业不错"
在上述文本中"北京交通大学"可以用"北交"代替,"交通信息工程及控制专业"可以用"交控专业"代替。
- "aaaaaaaaxxxxxxkkkkkkzzzzzzzzzz" 和 "8a6x6k10z"
在上述文本中有比较明显的局部重复,比如a出现了8次,z出现了10次,如果我们在分析了输入字符的分布规律之后,确定了"重复次数+字符"的规则,就可以进行替换了。
3.2 概率分布和数据编码
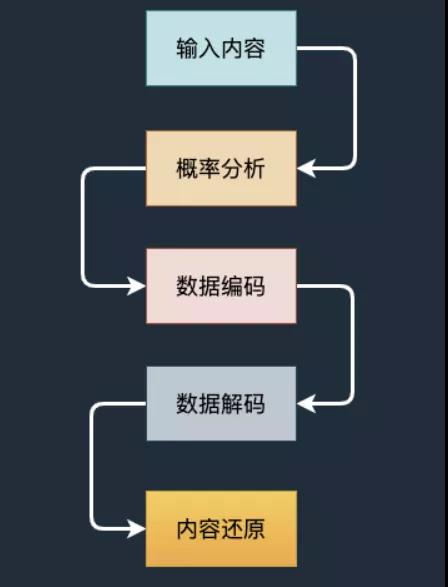
本质上来说,数据压缩就是找到待压缩内容的概率分布,再按照一定的编码算法,将那些出现概率高的部分代替成更短的形式。
所以输入内容重复的部分越多,就可以压缩地越小,压缩率越高,如果内容几乎没有重复完全随机,就很难压缩。
这个和我们平时优化代码性能的思路非常相似,热点代码的优化才能带来更大的收益。
3.3 数据压缩极限
前面提到了,用较短的字符串来替换较长的字符串就实现了压缩,那么如果对每次替换都使用最短的字符串,应该就可以认为是最优压缩了。
所以我们需要找到理论上的最短替换串的长度,换到二进制来说就是二进制的长度,这样就可以接近压缩极限了。
我们来分析一下:
- 抛硬币 只有正面和反面 两种情况 因此使用1位二进制 0和1 就可以
- 篮球比赛 存在胜/负/平 三种情况 因此需要使用2位二进制 00胜 01负 10平
- 猜生日月份 存在1-12月 12种情况 因此需要使用4位二进制 来表示各个月份
- 如果可能性有n个不同的值,那么替换串就需要log2(n)个二进制位来表示
假定内容由n个部分组成,每个部分出现概率分别为p1、p2、...pn,那么替代符号占据的二进制最少为:
- log2(1/p1) + log2(1/p2) + ... + log2(1/pn) = ∑ log2(1/pn)
可能的情况越多,需要的二进制长度可能就越长,对于n相等的两个文件,概率p决定了这个式子的大小:
- p越大,表明文件内容越有规律,压缩后的体积就越小;
- p越小,表明文件内容越随机,压缩后的体积就越大。
举例:有一个文件包含A, B, C个三种不同的字符,50%是A,30%是B,20%是C,文件总共包含1024个字符,每个字符所占用的二进制位的数学期望为:
- 0.5*log2(1/0.5) + 0.3*log2(1/0.3) + 0.2*log2(1/0.2)=1.49
求得压缩后每个字符平均占用1.49个二进制位,理论上最少需要1.49*1024=1526个二进制位,约0.1863KB,最终的压缩比接近于18.63%。
4. 霍夫曼编码简介
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
霍夫曼编码使用变长编码表对源符号进行编码,其中变长编码表是通过评估源符号出现的几率得到的。
出现几率高的字母使用较短的编码,出现几率低的字母使用较长的编码,这使得编码之后字符串的总长度降低。
4.1 前缀编码
霍夫曼编码除了使用变长码之外,还使用前缀编码来确保解码时的唯一性,举个例子:
A-0 C-1 B-00 D-01 则编码后为:000011010
当我们对它进行解码的时候,会发现 0000 可能对应多种解码方式,如 AAAA、AAB、ABA、BB。
霍夫曼树中叶子节点之间不存在父子关系,所以每个叶子节点的编码就不可能是其它叶子节点编码的前缀,这是非常重要的。
4.2 霍夫曼树简单构造
霍夫曼树是霍夫曼编码的重要组成部分,我们拿一个具体的例子来看下霍夫曼树的一点特性。
- 输入数据:"boob is bee boy"
- 字符串集合和频次统计
- 集合 {b,o,s,i,e,y}
- 频次 {b:4,o:3,e:2,i:1,y:1,s:1}
- 总计有6个字符,因此需要3位二进制
- 按照频率越高字符越短&前缀编码规则进行处理
- b:00
- o:01
- e:100
- i:101
- y:110
- s:111
- 注意:e并不是001,因为这样不符合前缀编码 b是e的父节点
霍夫曼编码的原理和实现还是比较复杂的,篇幅有限,后面单独写一篇文章详细介绍。
5. 本文小结
本文对数据压缩进行了简要的介绍,说明了数据压缩的本质和算法的基本原理,以及霍夫曼树的一些原理。
数据压缩和分析内容的概率分布以及编码有直接的关系,但是各个场景下输入内容的侧重点会有所不同,利用机器学习来处理数据压缩也是当前的一个热门话题。
篇幅有限,后续会重点展开一些细节,这篇就算抛砖引玉开头篇了。
我们下期见。










{kind=link}
![[[421668]]](https://s2.51cto.com/oss/202109/04/87b9463f778a8deb561ec0eda78ed8a9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}