
解析、迭代和生成系列文章:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
在Python中支持两种循环格式:while和for。这两种循环的类型不同:
- while是通过条件判断的真假来循环的
- for是通过in的元素存在性测试来循环的
更通俗地说,while是普通的步进循环,for是迭代遍历。
for的关键字在于"迭代"和"遍历"。首先要有容器数据结构(如列表、字符串)存储一些元素供迭代、遍历,然后每次取下一个元素通过in来测试元素的存在性(从容器中取了元素为何还要测试?因为容器可能会在迭代过程中临时发生改变),每次取一个,依次取下去,直到所有元素都被迭代完成,就完成了遍历操作。
这种迭代模式是一种惰性的工作方式。当要扫描内存中放不下的大数据集时,需要找到一种惰性获取数据项的方式,即按需一次获取一个数据项,而不是一次性收集全部数据。从此可以看出这种迭代模式最显著的优点是"内存占用少",因为它从头到尾迭代完所有数据的过程中都只需占用一个元素的内存空间。
Python中的迭代和解析和for都息息相关,本文先初探迭代。
内置类型的迭代
for循环可以迭代列表、元组、字符串(str/bytes/bytearray)、集合、字典、文件等类型。
>>> for i in [1,2,3,4]: print(i * 2,end=" ")
...
2 4 6 8
>>> for i in (1,2,3,4): print(i * 2,end=" ")
...
2 4 6 8
>>> for i in "abcd": print(i * 2,end=" ")
...
aa bb cc dd
>>> D=dict(a=1,b=2,c=3)
>>> for k in D:print("%s -> %s" % (k, D[k]))
...
a -> 1
b -> 2
c -> 3for循环其实比这更加通用。在Python中,只要是可迭代对象,或者更通俗地说是从左至右扫描对象的工具都可以进行这些迭代操作,这些工具有for、in成员测试、解析、map/zip等内置函数等。
关于什么是可迭代对象,后文会详细解释。
文件迭代操作
要读取一个文件有很多种方式:按字节数读取、按行读取、按段落读取、一次性全部读取等等。如果不是深入的操作文件数据,按行读、写是最通用的方式。
以下是下面测试时使用的文件a.txt的内容:
first line
second line
third line在Python中,readline()函数可以一次读取一行,且每次都是前进式的读取一行,读到文件结尾的时候会返回空字符串。
>>> f = open('a.txt')
>>> f.readline()
'first line\n'
>>> f.readline()
'second line\n'
>>> f.readline()
'third line\n'
>>> f.readline()
''readline()的操作就像是有一个指针,每次读完一行就将指针指向那一行的后面做下标记,以便下次能从这里开始继续向后读取一行。
除了readline(),open()打开的文件对象还有另一种方式__next__()可以一次向前读取一行,只不过__next__()在读取到文件结尾的时候不是返回空字符串,而是直接抛出迭代异常:
>>> f = open("a.txt")
>>> f.__next__()
'first line\n'
>>> f.__next__()
'second line\n'
>>> f.__next__()
'third line\n'
>>> f.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration内置函数next()会自动调用__next__(),也能进行迭代:
>>> f = open("a.txt")
>>> next(f)
'first line\n'
>>> next(f)
'second line\n'
>>> next(f)
'third line\n'
>>> next(f)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration要想再次读取这个文件,只能先重置这个指针,比如重新打开这个文件可以重置指针。
open()打开的文件是一个可迭代对象,它有__next__(),它可以被for/in等迭代工具来操作,例如:
>>> 'first line\n' in open('a.txt')
True所以更好的按行读取文件的方式是for line in open('file'),不用刻意使用readline()等函数去读取。
>>> for line in open('a.txt'):
... print(line,end='')
...
first line
second line
third line上面的print()设置了end='',因为读取每一行时会将换行符也读入,而print默认是自带换行符的,所以这里要禁止print的终止符,否则每一行后将多一空行。
上面使用for line in open('a.txt')的方式是最好的,它每次只读一行到内存,在需要读下一行的时候再去文件中读取,直到读完整个文件也都只占用了一行数据的内存空间。
也可以使用while去读取文件,并:
>>> f=open('a.txt')
>>> while True:
... line = f.readline()
... if not line: break
... print(line,end='')
...
first line
second line
third line在Python中,使用for一般比while速度更快,它是C写的,而while是Python虚拟机的解释代码。而且,for一般比while要更简单,而往往Python中的简单就意味着高效。
此外,还可以使用readlines()函数(和readline()不同,这是复数形式),它表示一次性读取所有内容到一个列表中,每一行都是这个大列表的一个元素。
>>> lines = open('a.txt').readlines()
>>> lines
['first line\n', 'second line\n', 'third line\n']因为存放到列表中了,所以也可以迭代readlines()读取的内容:
>>> for line in open('a.txt').readlines():
... print(line,end='')
...
first line
second line
third line这种一次性全部读取的方式在大多数情况下并非良方,如果是一个大文件,它会占用大量内存,甚至可能会因为内存不足而读取失败。
但并非必须要选择for line in open('a.txt')的方式,因为有些时候必须加载整个文件才能进行后续的操作,比如要排序文件,必须要拥有文件的所有数据才能进行排序。而且对于小文件来说,一次性读取到一个列表中操作起来可能会更加方便,因为列表对象有很多好用的方法。所以,不能一概而论地选择for line in open('a.txt')。
手动迭代
Python 3.X提供了一个内置函数next(),它会自动调用对象的__next__(),所以借助它可以进行手动迭代。
>>> f=open('a.txt')
>>> next(f)
'first line\n'
>>> next(f)
'second line\n'
>>> next(f)
'third line\n'
>>> next(f)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration可迭代对象、迭代协议和迭代工具的工作流程
这里只是解释这几个概念和__iter__()、__next__(),在后面会手动编写这两个方法来自定义迭代对象。
什么是迭代协议
参考手册:https://docs.python.org/3.7/library/stdtypes.html#iterator-types
只要某个类型(类)定义了__iter__()和__next__()方法就表示支持迭代协议。
__iter__()需要返回一个可迭代对象。只要定义了__iter__()就表示能够通过for/in/map/zip等迭代工具进行对应的迭代,也可以手动去执行迭代操作。
for x in Iterator
X in Iterator同时,可迭代对象还可以作为某些函数参数,例如将可迭代对象构建成一个列表list(Iterator)来查看这个可迭代对象会返回哪些数据:
L = list(Iterator)需要注意的是,for/in/map/zip等迭代工具要操作的对象并不一定要实现__iter__(),实现了__getitem__()也可以。__getitem__()是数值索引迭代的方式,它的优先级低于__iter__()。
__next__()方法用于向前一次返回一个结果,并且在前进到结尾的地方触发StopIteration异常。
再次说明,只要实现了这两个方法的类型,就表示支持迭代协议,可以被迭代。
例如open()的文件类型:
>>> f=open('a.txt')
>>> dir(f)
[... '__iter__', ... '__next__', ...]但如果看下列表类型、元组、字符串等容器类型的属性列表,会发现没有它们只有__iter__(),并没有__next__():
>>> dir(list)
[... '__iter__', ...]
>>> dir(tuple)
[... '__iter__', ...]
>>> dir(str)
[... '__iter__', ...']
>>> dir(set)
[... '__iter__', ...]
>>> dir(dict)
[... '__iter__', ...]但为什么它们能进行迭代呢?继续看下文"可迭代对象"的解释。
什么是迭代对象和迭代器
对于前面的容器类型(list/set/str/tuple/dict)只有__iter__()而没有__next__(),但却可以进行迭代操作的原因,是这些容器类型的__iter__()返回了一个可迭代对象,而这些可迭代对象才是真的支持迭代协议、可进行迭代的对象。
>>> L=[1,2,3,4]
>>> L_iter = L.__iter__()
>>> L_iter
<list_iterator object at 0x000001E53A105400>
>>> dir(L_iter)
[... '__iter__', ... '__next__', ...]
>>> L.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute '__next__'
>>> L_iter.__next__()
1
>>> L_iter.__next__()
2
>>> L_iter.__next__()
3
>>> L_iter.__next__()
4所以,对于容器类型,它们是通过__iter__()来返回一个迭代对象,然后这个可迭代对象需要支持迭代协议(有__iter__()和__next__()方法)。
也就是说,所谓的迭代对象是通过__iter__()来返回的。迭代对象不一定可迭代,只有支持迭代协议的迭代对象才能称为可迭代对象。
迭代器则是迭代对象的一种类型统称,只要是可迭代对象,都可以称为迭代器。所以,一般来说,迭代器和可迭代对象是可以混用的概念。但严格点定义,迭代对象是iter()返回的,迭代器是__iter__()返回的,所以它们的关系是:从迭代对象中获取迭代器(可迭代对象)。
如果要自己定义迭代对象类型,不仅需要返回可迭代对象,还需要这个可迭代对象同时实现了__iter__()和__next__()。
正如open()返回的类型,它有__iter__()和__next__(),所以它支持迭代协议,可以被迭代。再者,它的__iter__()返回的是自身,而自身又实现了这两个方法,所以它是可迭代对象:
>>> f = open('a.txt')
>>> f.__iter__() is f
True所以,如果想要知道某个对象是否可迭代,可以直接调用iter()来测试,如果它不抛出异常,则说明可迭代(尽管还要求实现__next__())。
迭代工具的工作流程
像for/in/map/zip等迭代工具,它们的工作流程大致遵循这些过程(并非一定如此):
- 在真正开始迭代之前,首先会通过iter(X)内置函数获取到要操作的迭代对象Y
- 例如
it = iter([1,2,3,4])
- iter(X)会调用X的
__iter__(),前面说过这个方法要求返回迭代对象
- 如果没有
__iter__(),则iter()转而调用__getitem__()来进行索引迭代
- 例如
- 获取到迭代对象后,开始进入迭代过程。在迭代过程中,每次都调用next(Y)内置函数来生成一个结果,而next()会自动调用Y的
__next__()
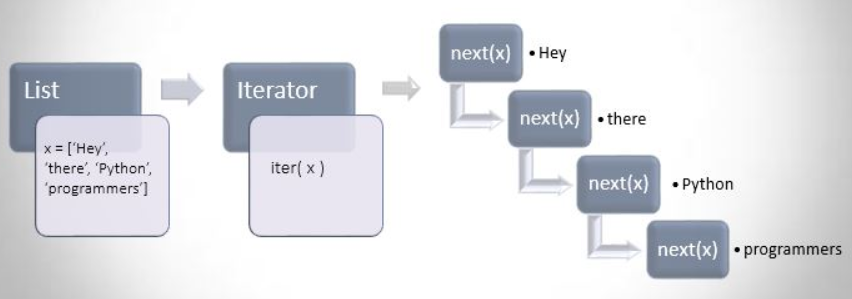
如果类型对象自身就实现了__iter__()和__next__(),则这个类型的可迭代对象就是自身。就像open()返回的文件类型一样。
如果自身只是实现了__iter__()而没有__next__(),那么它的__iter__()就需要返回实现了__iter__()和__next__()的类型对象。这种类型的对象自身不是迭代器,就像内置的各种可迭代容器类型一样。
关于iter(), __iter__(), next(), __next__(),它们两两的作用是一致的,只不过基于类设计的考虑,将__iter__()和__next__()作为了通用的类型对象属性,而额外添加了iter()和next()来调用它们。
for/map/in/zip等迭代工具是自动进行迭代的,但既然理解了可迭代对象,我们也可以手动去循环迭代:
>>> L=[1,2,3,4]
>>> for i in L:print(i,end=" ")
...
1 2 3 4
L = [1,2,3,4]
I = iter(L)
while True:
try:
x = next(I)
except StopIteration:
break
print(x,end=" ")注意:
- 每一个迭代对象都是一次性资源,迭代完后就不能再次从头开始迭代,如果想要再次迭代,必须使用iter()重新获取迭代对象
- 每次迭代时,都会标记下当前所迭代的位置,以便下次从下一个指针位置处继续迭代
可迭代对象示例:range和enumerate
range()返回的内容是一个可迭代对象,作为可迭代对象,可以进行上面所描述的一些操作。
>>> 3 in range(5)
True
>>> for i in range(5):print(i,end=" ")
...
0 1 2 3 4
>>> list(range(5))
[0, 1, 2, 3, 4]
>>> R = range(5)
>>> I = iter(R)
>>> next(I)
0
>>> next(I)
1
>>> next(I)
2
>>> next(I)
3
>>> next(I)
4
>>> next(I)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIterationenumerate()返回的也是可迭代对象:
>>> E = enumerate('hello')
>>> E
<enumerate object at 0x000001EF6BFD1F78>
>>> I = iter(E)
>>> next(I)
(0, 'h')
>>> next(I)
(1, 'e')
>>> next(I)
(2, 'l')
>>> next(I)
(3, 'l')
>>> next(I)
(4, 'o')
>>> next(I)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration可迭代对象实例:字典的可迭代视图
字典自身有__iter__(),所以dict也是可迭代的对象,只不过它所返回的可迭代对象是dict的key。
>>> D = dict(one=1,two=2,three=3,four=4)
>>> I = iter(D)
>>> next(I)
'one'
>>> next(I)
'two'
>>> next(I)
'three'
>>> next(I)
'four'
>>> next(I)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration除此之外,dict还支持其它可迭代的字典视图keys()、values()、items()。
>>> hasattr(D.keys(),"__iter__")
True
>>> hasattr(D.values(),"__iter__")
True
>>> hasattr(D.items(),"__iter__")
True







