
Python库-pandas详解
1. pandas介绍
pandas 是用于数据挖掘的Python库
- 便捷的数据处理能力
- 独特的数据结构
- 读取文件方便
- 封装了matplotlib的画图和numpy的计算
pandas的数据结构
- Series
- Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。由索引(index)和列组成。
- DataFrame
- DataFrame 是一个表格型的数据结构,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典。
案例应用
创建一个符合正态分布的10个股票5天的涨跌幅数据,使用pandas中的数据结构 DataFrame() 处理数据
# 导入库import numpy as npimport pandas as pd# 创建一个符合正态分布的10个股票5天的涨跌幅数据stocks = np.random.normal(0, 1, [10, 5])# 使用pandas中的数据结构 DataFrame() 处理数据stocks_rise = pd.DataFrame(stocks)# 设置行索引,获取行数 stocks_rise.shape[0] 进行遍历 列表生成式index_row = ['股票{}'.format(i+1) for i in range(stocks_rise.shape[0])]# 设置列索引,日期是一个时间序列,为了简便,使用pd.date_range()生成一组连续的时间序列# pd.date_range(start,end,periods,freq) start:开始时间, end:结束时间# periods:时间天数, freq:递进单位,默认1天,'B'默认略过周末index_col = pd.date_range(start='20220201',periods=stocks_rise.shape[1],freq='B')# 添加索引,注意数据是ndarray数据 index表示行索引,columns表示列索引data = pd.DataFrame(stocks, index=index_row, columns=index_col)print(data) 2022-02-01 2022-02-02 2022-02-03 2022-02-04 2022-02-07股票1 -2.054041 -1.170757 0.162393 0.253333 -1.638837股票2 -1.463734 0.408459 0.530070 -0.925281 1.454630股票3 -0.511517 -0.827591 -2.076265 0.139486 0.658707股票4 -1.698789 0.250902 -0.624713 1.378845 -1.672292股票5 0.683233 -1.083694 0.810567 0.421215 1.375385股票6 -0.296111 -0.946959 0.836536 -1.179879 -0.397406股票7 0.017772 0.180210 2.022776 0.436337 -1.555866股票8 0.638262 -0.790932 1.077822 -1.746631 -0.591360股票9 -0.681391 -0.613255 -1.849094 0.438304 -0.503742股票10 -0.243500 -1.733623 -1.137840 0.124976 -0.4157272. Series
pd.Series( data, index, dtype, name, copy)
参数说明:data:一组数据(ndarray 类型)。index:数据索引标签,如果不指定,默认从 0 开始。dtype:数据类型,默认会自己判断。name:设置名称。copy:拷贝数据,默认为 False。Series实例
# 通过数组创建Seriess = pd.Series([6, 5, 2], index=['x', 'y', 'z'])print(s)x 6y 5z 2# 通过字典创建Seriess = pd.Series({ 'day': 2, 'month': 2, 'year': 2022})print(s)day 2month 2year 2022dtype: int64# 通过索引操作数据print(s['year'])20223. DataFrame
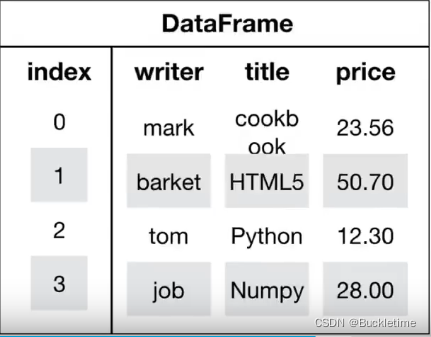
3.1 DataFrame结构
DataFrame对象既有行索引,又有列索引
- 行索引:表明不同行,横向索引,叫index,axis=0
- 列索引:表明不同列,纵向索引,叫columns,axis=1
3.2 DataFrame属性与方法
- shape DataFrame的形状
- index DataFrame行索引
- columns DataFrame列索引
- values DataFrame的值
- T DataFrame转置
- head(n) DataFrame的前n行,默认为前5行
- tail(n) DataFrame的后n行,默认为后5行
print(data.shape) # (10, 5)print(data.index)# Index(['股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9', '股票10'], dtype='object')print(data.columns)# DatetimeIndex(['2022-02-01', '2022-02-02', '2022-02-03', '2022-02-04',# '2022-02-07'],# dtype='datetime64[ns]', freq='B')print(data.values)print(data.T)3.2 DataFrame索引的设置
1 修改行列索引值
- 必须整体全部修改,不能单独修改某个索引
index_row2 = ['股票_{}'.format(i + 1) for i in range(stocks_rise.shape[0])]data.index = index_row2print(data)2 重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引
# 重设索引print(data.reset_index(drop=False))3 以某列值设为新的索引
- set_index(keys,drop=True)
- keys:列索引名称或者列索引名称的列表
- drop:默认为True,当作新的索引,删除原来索引
# 创建df = pd.DataFrame({ 'month': [1, 4, 7, 10], 'year': [2018, 2019, 2020, 2021], 'sale': [55, 40, 84, 33]})print(df) month year sale0 1 2018 551 4 2019 402 7 2020 843 10 2021 33# 以月份设置新的索引print(df.set_index('month')) year salemonth 1 2018 554 2019 407 2020 8410 2021 33# 设置多个索引,以年和月份# 如果设置索引是两个的时候,就是multiIndexprint(df.set_index(['year', 'month'])) saleyear month 2018 1 552019 4 402020 7 842021 10 334. 基本数据操作
4.1 索引重命名
- rename(mapper=None,inplace=False)
- mapper:映射结构,修改columns或index要传入一个映射体,可以是字典、函数
- inplace:默认为False,不改变数据,返回一个新的DataFrame
4.2 通过索引操作数据
1. 直接使用行列索引(先列后行)
- 先行后列会报错
- 不支持切片,会报错
stocks = np.random.normal(0, 1, [10, 5])stocks_rise = pd.DataFrame(stocks)index_row = ['股票{}'.format(i + 1) for i in range(stocks_rise.shape[0])]index_col = pd.date_range(start='20220201', periods=stocks_rise.shape[1], freq='B')data = pd.DataFrame(stocks, index=index_row, columns=index_col)print(data.head()) 2022-02-01 2022-02-02 2022-02-03 2022-02-04 2022-02-07股票1 0.663384 1.936687 1.992576 2.009280 -0.723381股票2 -2.441452 0.081647 -0.738524 -0.620358 -1.930378股票3 2.026646 -0.324842 -0.478456 -0.840363 1.492842股票4 -0.188968 -1.180816 0.733197 -0.078608 -1.056264股票5 1.219254 -1.738242 0.473682 0.288252 3.513113# 索引先列后行获取数据print(data['2022-02-03']['股票3'])-0.47845617563179627# print(data['股票3']['2022-02-03']) # 先行后列会报错# print(data[:1, :2]) # 不支持切片,会报错2. 结合loc或iloc使用索引(先行后列)
- loc 通过索引名称访问
- iloc 通过索引下标访问,支持切片
print(data.loc['股票3']['2022-02-03']) print(data.iloc[1, 1])print(data.iloc[:3, :4])- loc或iloc还可以进行组合索引访问
# 获取前5行,两列的值print(data.loc[data.index[:5], ['2022-02-01', '2022-02-02']])print(data.iloc[0:5, data.columns.get_indexer(['2022-02-01', '2022-02-02'])])4.3 排序
1. sort_values(by=,ascending=) 对内容进行排序
- by:根据单个键或者多个键(优先级从前到后)进行排序,默认升序 ascending=True
- ascending=False,降序
print(data.sort_values(by='2022-02-01', ascending=False))print(data.sort_values(by=['2022-02-01', '2022-02-02'], ascending=False))2. sort_index(ascending=) 对索引进行排序
- 默认升序 ascending=True, 降序为False
print(data.sort_index(ascending=False))说明:Series的排序方法与DataFrame方法一致,因为只有一列,也不用指定键,只需要指定是升序或降序5. DataFrame运算
5.1 算术运算
和一般算数运算方法类似,举几个例子
import pandas as pddf = pd.DataFrame({ 'month': [1, 4, 7, 10], 'year': [2018, 2019, 2020, 2021], 'sale': [55, 40, 84, 33]})n = df['sale'][0] # 55print(n.__add__(2)) # 加法运算 <=> +print(n.__sub__(2)) # 减法运算 <=> -print(n.__mul__(2)) # 乘法运算 <=> *print(n.__divmod__(2)) # 除余,得到商和余数 (商, 余数)print(n.__mod__(2)) # 模运算(余数)<=> %print(n.__abs__()) # 绝对值运算5.2 逻辑运算
- 逻辑运算符号 < > | &
- 获取逻辑运算结果
- 将逻辑运算结果作为筛选条件进行数据筛选
print(df) month year sale0 1 2018 551 4 2019 402 7 2020 843 10 2021 33# 获取逻辑运算结果print(df['sale'] > 50)0 True1 False2 True3 False# 逻辑运算结果可以作为筛选的条件print(df[df['sale'] > 50]) Name: sale, dtype: bool month year sale0 1 2018 552 7 2020 84- 逻辑运算函数
- query(expr) 通过条件字符串进行查询符合条件的数据
- isin(values) 对数据进行逻辑判断,判断数据是否在指定的values中
print(df.query('sale > 35 & sale < 80')) month year sale0 1 2018 551 4 2019 40print(df['sale'].isin([30, 40]))0 False1 True2 False3 FalseName: sale, dtype: bool5.3 统计运算
- describe() 综合分析,统计数量count,平均值mean,标准差std,最大值,最小值等
print(data.head().describe()) 2022-02-01 2022-02-02 2022-02-03 2022-02-04 2022-02-07count 5.000000 5.000000 5.000000 5.000000 5.000000mean 0.731207 0.016387 -0.292730 -0.050105 0.491857std 0.692347 1.184870 1.038632 0.897436 0.808612min -0.019900 -1.273726 -1.526506 -0.766793 -0.41600625% 0.558542 -0.963643 -1.228403 -0.563485 0.04399950% 0.581686 -0.036380 -0.031193 -0.553368 0.13653875% 0.665749 0.797005 0.541065 0.229670 1.331016max 1.869961 1.558681 0.781386 1.403449 1.363740- 描述性统计函数
对于单个函数去统计的时候,坐标轴还是按照默认columns(axis=0),如需要对行统计,指定axis=1
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| idxmax | 最大值的索引 |
| idxmin | 最小值的索引 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积 |
| cumsum() | 计算累计和 |
| cumprod() | 计算累计积 |
- 其他统计函数
| 函数名称 | 描述说明 |
|---|---|
| pct_change() | 百分比函数:将每个元素与其前一个元素进行比较,并计算前后数值的百分比变化 |
| cov() | 协方差函数:用来计算 Series 对象之间的协方差。该方法会将缺失值(NAN )自动排除 |
| corr() | 相关系数:计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强,会排除NAN 值 |
5.4 自定义运算
apply(func,axis)
- func:自定义运算函数
- axis:默认为0,对列运算
6. pandas画图
对象.plot(x=None,y=None,kind=‘line’)
- x和y表示标签或者位置,默认为None
- kind:表示绘图的类型,默认为line,折线图
- line:折线图
- bar/barh:柱状图
- hist:直方图
- pie:饼状图
- area:区域图
- scatter:散点图
import matplotlib.pyplot as pltrise = data.loc['股票1'].cumsum()print(rise)rise.plot()# 画图plt.show()# 显示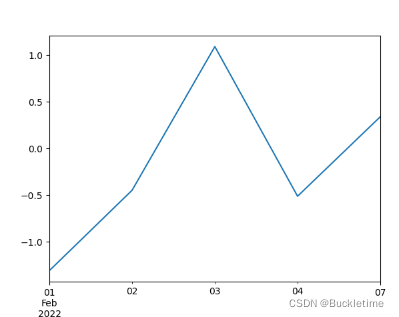
7. 文件的读取和存储
pandas支持的常用文件类型包括:HDF5、CSV、SQL、XLS、JSON等
1.CSV
- pd.read_csv(‘filepath_or_buffer’, usecols=[]) 读取csv文件数据
- filepath_or_buffer:文件路径
- sep:分隔符,默认为’,’
- usecols:指定读取的列名,列表形式
import pandas as pddata = pd.read_csv(r'../../fodder/stocks.csv', usecols=['open', 'high', 'low', 'close'])print(data.head()) open high low close0 29.76 29.97 29.52 29.961 28.49 29.51 28.42 29.502 28.76 28.95 28.47 28.503 28.41 28.95 28.32 28.904 28.37 28.61 28.33 28.36- df.to_csv(path_or_buf,columns=[],index=True,mode=‘w’) 将数据存储到csv文件中
- path_or_buf:文件存放的路径
- sep:分隔符,默认为’,’
- columns:列,列表形式
- mode:‘w’:重写,‘a’:追加
- header:是否写进列索引值
- index:是否写进行索引,默认True写进行索引,会将行索引变成一列数据
- encoding:编码格式,默认为None
# 将前十行数据写进新的文件中 index设置False,不写行索引data[:10].to_csv(r'../../fodder/test.csv', columns=['open', 'close'], index=False)# 查看写进文件的数据data2 = pd.read_csv(r'../../fodder/test.csv')print(data2) open close0 29.76 29.961 28.49 29.502 28.76 28.503 28.41 28.904 28.37 28.365 27.48 28.346 27.66 27.847 28.03 27.558 28.65 28.379 28.39 28.842.HDF5
读取HDF5文件(.h5)需要安装tables模块
- pd.read_hdf(path_or_buf, key=None) 读取HDF5文件
- path_or_buf:文件路径
- key:读取的键
- df.to_hdf(path_or_buf, key) 写入HDF5文件
- path_or_buf:文件路径
- key:写入文件时,必须指定一个键
# 读取.h5文件数据data = pd.read_hdf(r'../../fodder/stocks.h5')print(data.head())# 将数据写入.h5文件data.to_hdf(r'../../fodder/test.h5', key='a')data2 = pd.read_hdf(r'../../fodder/test.h5', key='a')print(data2.head())3.JSON
- pd.read_jsonf(path_or_buf, orient=None,typ=‘frame’,lines=False) 读取json文件
- path_or_buf:文件路径
- orient:指定数据存储的json形式 ,{‘split’,‘records’,‘index’,‘columns’,‘valuse’}
- typ:默认frame,指定转换成的对象类型Series或者DataFrame
- lines:默认False,按照每行读取json
- pd.to_jsonf(path_or_buf, orient=None,lines=False) 存储json文件
- path_or_buf:文件路径
- orient:指定数据存储的json形式
- lines:默认False,一个对象存储为一行。一般设置为Ture
# 读取json文件data = pd.read_json(r'../../fodder/33510.json', orient='records', lines=True)print(data.head())# 写入json文件data.to_json(r'../../fodder/test.json', orient='records', lines=True)data2 = pd.read_json(r'../../fodder/test.json')print(data2.head())8. 数据的高级处理
8.1 缺失值处理
缺失值NaN的类型是float
print(type(np.NAN))<class 'float'>1. 判断数据是否有缺失值
- pd.isnull(df)
- pd.notnull(df)
# 读取xls数据data = pd.read_excel(r'../Python/demo/reptile/豆瓣电影TOP250/豆瓣电影TOP250.xls')# 只要包含缺失值,就为Truenp.any(pd.isnull(data)) # True2. 处理NaN
- 删除缺失值 dropna(inplace=False),前提是缺失值的类型必须是np.NaN
# dropna()方法可以指定是否在原数据上进行删除 默认inplace=False 不修改原数据newdata = data.dropna() np.any(pd.isnull(newdata)) # False- 替换缺失值 fillna(value,inplace=False)
- value:替换后的值
- inplace:默认False,表示不改变原数据,True表示在原数据上直接替换
for item in data.columns:# print(item) # 遍历所有列索引 # 判断该列中是否含有缺失值 if np.any(pd.isnull(data[item])): # print(item) # 对该列中的缺失值进行替换 data[item].fillna(value="this is queshizhi", inplace=True)3. 缺失值不是NaN的情况,如默认标记符号
比如数据中存在"?"符号,则可以先将符号替换为NaN,再进行处理。
- 替换 replace(to_replace,value) ,在原数据上直接替换
- to_replace:替换前的值
- value:替换后的值
# 替换为np.NaNdata.replace(to_replace="?", value=np.NaN)# 删除缺失值 在原数据上直接删除data.dropna(inplace=True)8.2 数据离散化处理
1. 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数,离散化方法经常作为数据挖掘的工具。
2. 什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为着干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
假设按照身高分几个区间段:150—165,165~180.180—195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个“哑变量“矩阵
3. 数据离散化处理
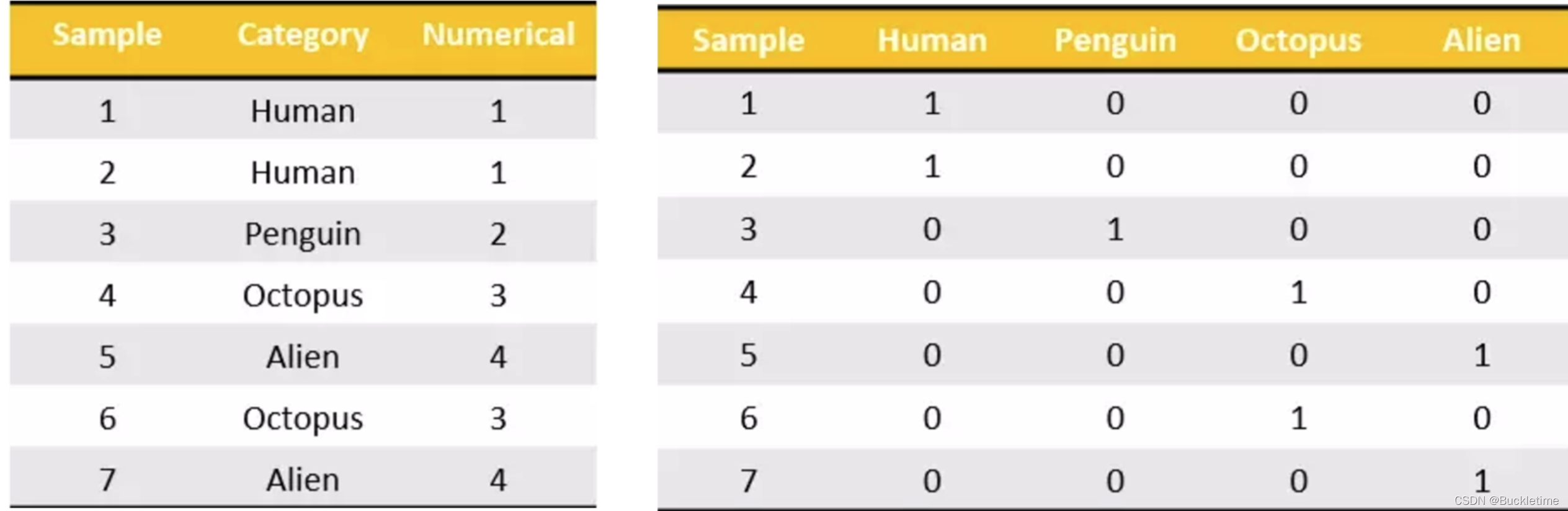
one-hot编码介绍
One-Hot编码,又称为一位有效编码,是分类变量作为二进制向量的表示。one-hot 编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。别名:哑变量,热独编码
(1) 将分类值映射到整数值。
(2) 然后,每个整数值被表示为二进制向量,除了整数的索引之外,其他都是零值,它被标记为1。
例子:把下图中左边的表格转化为使用右边形式进行表示:
方法
- pd.qcut(data,q):对数据进行分组,一般与value_counts搭配使用
- data:需要分组的数据
- q:分组数量,表示自行将数据分成数量相近的q组
- pd.cut(data,bins):自定义分组
- bins:自定义分组区间
- series.value_counts():统计个数
- pd.get_dummies(data, prefix=None):获取数据的one-hot编码矩阵
- prefix:分组名字
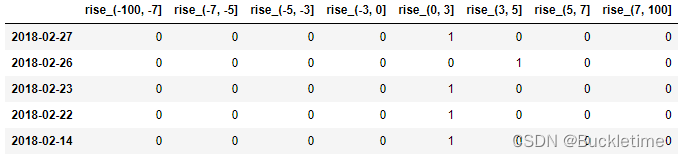
案例:对股票每日的涨跌幅(“p_change”)数据进行离散化
# 1. 先读取股票的数据,筛选出p_change数据data = pd.read_csv('../Python/fodder/stock_day.csv')data_p = data['p_change']# 2. 将股票涨跌幅数据进行分组并统计qcut = pd.qcut(data_p, 10)# 分组 自行分成10组2018-02-27 (1.738, 2.938]2018-02-26 (2.938, 5.27]2018-02-23 (1.738, 2.938]2018-02-22 (0.94, 1.738]2018-02-14 (1.738, 2.938] ... qcut.value_counts()# 统计(-10.030999999999999, -4.836] 65(-0.462, 0.26] 65(0.26, 0.94] 65(5.27, 10.03] 65(-4.836, -2.444] 64(-2.444, -1.352] 64(-1.352, -0.462] 64(1.738, 2.938] 64(2.938, 5.27] 64(0.94, 1.738] 63# 可以自定义分组区间bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]cut = pd.cut(data_p, bins)cut.value_counts()(0, 3] 215(-3, 0] 188(3, 5] 57(-5, -3] 51(5, 7] 35(7, 100] 35(-100, -7] 34(-7, -5] 28# 3. 得出one-hot编码矩阵pd.get_dummies(cut, prefix="rise").head()one-hot编码矩阵前5行如图所示:
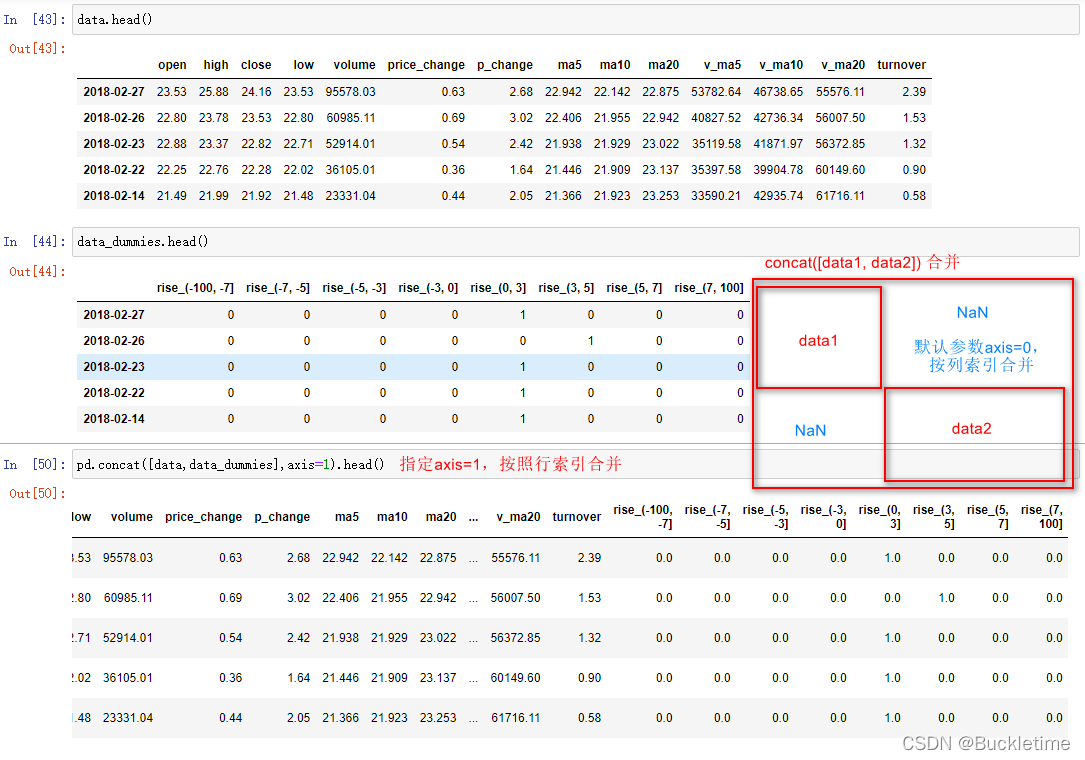
8.3 数据合并
- pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引(默认),axis=1为行索引
将处理好的one-hot编码矩阵与原数据合并
- pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
- left:左表
- right:右表
- how:指定合并的方式 ,与数据库表的连接方式原理一样
- inner:内连接,默认连接方式
- outer:外连接
- left:左连接
- right:右连接
- on: 指定键
- left_on=None, right_on=None:指定左右键
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'], 'key2': ['K0', 'K0', 'K0', 'K0'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']})# 默认内连接, 指定'key1', 'key2'pd.merge(left, right, on=['key1', 'key2'])
# 外连接pd.merge(left, right, how='outer', on=['key1', 'key2'])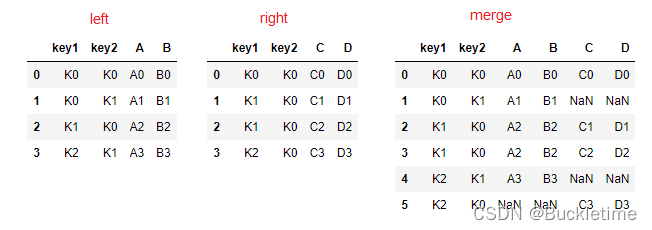
# 左连接pd.merge(left, right, how='left', on=['key1', 'key2'])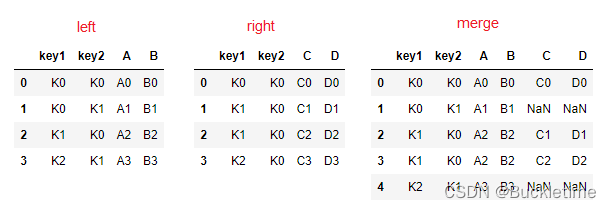
# 右连接pd.merge(left, right, how='right', on=['key1', 'key2'])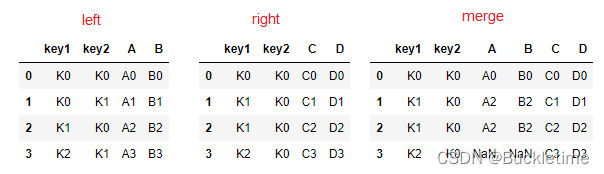
8.4 交叉表与透视表
透视表(pivot table)数据汇总分析工具交叉表(crosstab)是一种用于计算分组频率的特殊透视表用于计算一列数据对于另外一列数据的分组频率(寻找两个列之间的关系)- pd.crosstab(value1, value2) 交叉表
案例分析:探究星期几跟股票涨跌的关系
准备两列数据,星期数据以及涨跌数据
# 先把对应的日期找到星期几weekday = pd.to_datetime(data.index).weekday# 增加一列weekday 表示星期几 星期一至星期日 分别为0~6data['weekday'] = weekday# 把p_change按照大小去分个类0为界限up_or_down = np.where(data['p_change'] > 0, 1, 0)# 增加一列up_or_down,表示涨跌情况 1涨,0跌data['up_or_down'] = up_or_down通过交叉表找寻两列数据的关系
# 通过交叉表找寻两列数据的关系result= pd.crosstab(data['weekday'], data['up_or_down'])up_or_down01weekday0636215576261713636545968此时得到的result只是每天涨跌的次数,并没有得到比例,可以通过先求和,再计算百分比
# 算数运算,先求和sum = result.sum(axis=1)# 进行相除操作,得出比例per = result.div(sum, axis=0)up_or_down01weekday00.5040000.49600010.4198470.58015320.4621210.53787930.4921880.50781240.4645670.535433画图,查看效果
# stacked=True 表示堆积显示pro.plot(kind='bar', stacked=True)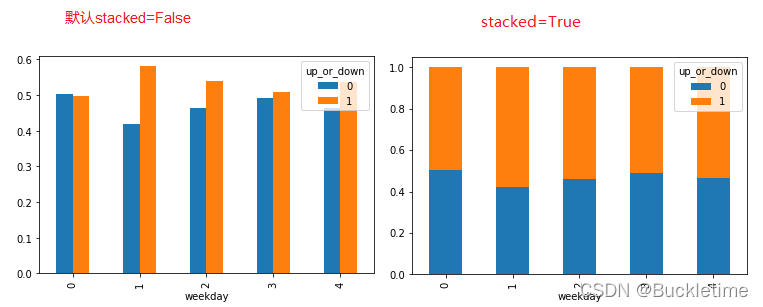
- DataFrame.pivot_table([], index=[]) 透视表
使用透视表,刚才的过程更加简单,可以直接得到一组数据占另一组数据的百分比
per = data.pivot_table(['up_or_down'], index='weekday')up_or_downweekday00.49600010.58015320.53787930.50781240.5354338.5 分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
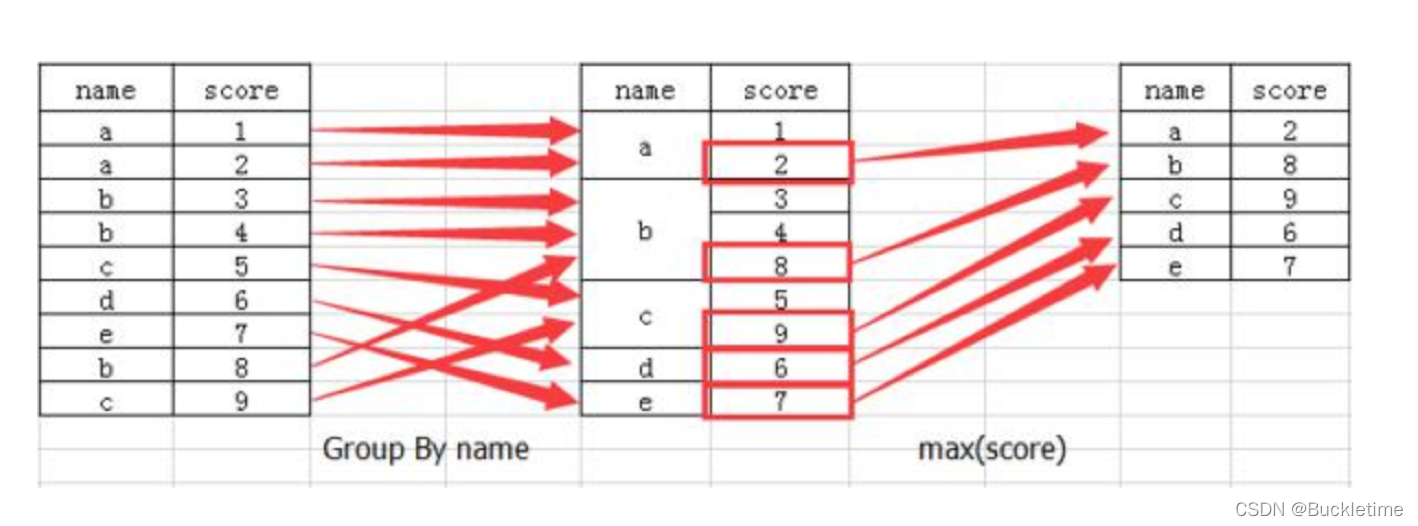
DataFrame.groupby(key, as_index=True)
- key:分组的列数据,可以多个
- as_index:是否进行索引,默认True
案例:不同颜色的不同笔的价格数据,对颜色分组,价格进行聚合
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})# 对颜色分组,price1进行聚合,求均值col.groupby('color')['price1'].mean()# 方法1 常用col['price1'].groupby(col['color']).mean()# 方法2colorgreen 2.025red 2.380white 5.560来源地址:https://blog.csdn.net/weixin_45698637/article/details/122766366








