
一、awk概述
awk是专门为文本处理设计的编程语言,是一门数据驱动的编程语言,与sed类似都是以数据驱动的【行处理】软件,主要用于【数据扫描】、【过滤】、【统计汇总】工作,数据可以来自【标准输入】、【管道】或者【文件】。
awk在20世纪70年代诞生与贝尔实验室。现在使用的版本是1988年发布的Gnu awk。
二、基础语法
2.1.记录与字段
awk是一种【处理文本文件】的编程语言,文件的每行数据都被称为【记录】。默认以【空格】或【制表符】为分隔符,每条记录被分成【若干字段(列)】,awk每次从文件中读取【一条记录】。
语法格式:
awk [选项] ‘条件{动作} 条件{动作} ... ...’ 文件名
awk语法由一系列条件和动作组成,在花括号内可以有多个动作,多个动作之间用【分号】分隔,在多个条件和动作之间可以有若干【空格】,也可以没有。
如果没有指定条件则匹配【所有数据】,如果没有指定动作则默认为【print打印】。
2.2.常用的内置变量
| 变量 | 说明 |
| -F | 指定分隔符 |
| -v | 指定变量和默认值 |
| $NF | 代表最后一个字段 |
| NR | 代表第几行 |
| && | 逻辑与 |
| || | 逻辑或 |
| FS | 输入字段分隔符,与-F分隔符一样 |
| OFS | 输出字段分隔符 |
| RS | 输入记录分隔符 |
| $0 | 整行,也就是当前记录 |
| ..N | 第一个字段到第N个字段,字段间由FS分隔 |
2.2.1. 内置变量表(全)
| 属性 | 说明 |
| $0 | 整行,也就是当前记录 |
| $1~$n | 当前记录的第1个到第n个字段,字段间由FS分隔 |
| FS | 输入字段分隔符, 默认是空格 |
| NF | 当前记录中的字段个数,就是有多少列 |
| NR | 已经读出的记录数,就是行号,从1开始计数 |
| RS | 输入的记录的分隔符,默认为换行符 |
| OFS | 输出的字段的分隔符,默认是空格 |
| ORS | 输出的记录的分隔符,默认为换行符 |
| ARGC | 命令行参数个数 |
| ARGV | 命令行参数数组 |
| FILENAME | 当前输入文件的名字 |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| ARGIND | 当前被处理文件的ARGV标志符 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | UNIX系统环境变量关联数组 |
| ERRNO | UNIX系统错误消息 |
| FIELDWIDTHS | 输入字段宽度的空白分隔字符串 |
| FNR | 各文件分别计数的记录数 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| RLENGTH | 由match函数所匹配的字符串长度 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
示例代码:
# free | awk '{print $2}' #逐行打印第2列used30623640free | awk '{print NR}' #输出行号free | awk '{print NF}' #输出每行数据的列数awk '{print $NF}' /tmp/hosts #打印每行数据的最后一列awk '{print $(NF-1)}' /tmp/hosts #打印每行倒数第二列cp /etc/hosts /tmp/hostsawk '{print $0}' /tmp/hosts #打印每行全部内容本文测试文件说明:
/etc/hosts 的内容:
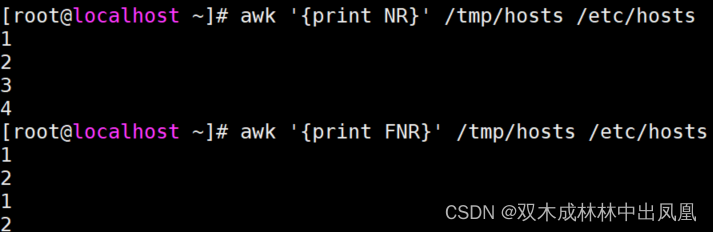
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6NR和FNR说明
同样是输出行号,NR将所有文件的数据视为【一个数据流】;
而FNR则是将多个文件的数据视为【独立的若干个数据流】,遇到新文件时行号【从1开始重新】递增。
如下图所示:
2.3. 自定义变量
示例代码如下
awk -v x="bob" -v y=10 '{print x,y}' /tmp/hosts运行结果如下图:
![]()
运行说明:输出2行是因为文件:/tmp/hosts一共2行。
2.4.调用系统变量
示例代码:
awk -v shell=$SHELL '{print shell}' /tmp/hosts #或者awk '{print "'$SHELL'"}' /tmp/hosts #双引号加单引号组合能正确获取系统变量运行结果如下图:
说明:输出2行是因为文件:/tmp/hosts一共2行。
2.5.自定义分隔符
默认以【空格】、【换行符】、【制表符】作为分隔符,使用-F可以指定分隔符
awk -F: '{print $1}' /etc/passwd #以冒号作为分隔符awk -F '?' '{ print $1}' files #以问号作为分隔符awk -F"[:,_]" '{print $1}' /etc/passwd #使用集合定义分隔符,分隔符为:: , _ 。 【不包含中括号】。说明:
-F后面直接加冒号,可以指定以冒号作为分隔符;
可以用单引号括起来,表示指定一个分隔符;
可以使用正则表达式指定分隔符;
语法: awk -F '正则表达式' 'pattern action' file-name
示例代码如下:
[root@rockylinux tmp]# [root@rockylinux tmp]# cat web.txt www1runoob2comwww3baidu4comwww5bilibili6comhttp://www.nothing.com/pages/help.jsp[root@rockylinux tmp]# [root@rockylinux tmp]# [root@rockylinux tmp]# awk -F '[0-9]' '{print $1, $2, $3, $4, $5}' web.txt www runoob com www baidu com www bilibili com http://www.nothing.com/pages/help.jsp [root@rockylinux tmp]# [root@rockylinux tmp]# [root@rockylinux tmp]# awk -F '//|/' '{print $1, $2, $3, $4, $5}' web.txt www1runoob2com www3baidu4com www5bilibili6com http: www.nothing.com pages help.jsp [root@rockylinux tmp]# [root@rockylinux tmp]# [root@rockylinux tmp]# awk -F '//|/|:' '{print $1, $2, $3, $4, $5}' web.txt www1runoob2com www3baidu4com www5bilibili6com http www.nothing.com pages help.jsp[root@rockylinux tmp]# [root@rockylinux tmp]# [root@rockylinux tmp]# awk -F '([ot]{2})' '{print $1, $2, $3, $4, $5}' web.txt www1run b2com www3baidu4com www5bilibili6com h p://www.n hing.com/pages/help.jsp [root@rockylinux tmp]# [root@rockylinux tmp]# [root@rockylinux tmp]# awk -F '[ot]{2}' '{print $1, $2, $3, $4, $5}' web.txt www1run b2com www3baidu4com www5bilibili6com h p://www.n hing.com/pages/help.jsp [root@rockylinux tmp]# 2.6.内置变量RS、ORS、OFS
RS:
内置变量RS保存的是输入数据的行分隔符,默认为\n,可以指定其它字符作为行分隔符
awk -v RS="." '{print $1}' /tmp/hosts #指定.作为行分隔符ORS:
保存的是输出记录的分隔符
awk -v ORS="-" '{print $1}' /tmp/hosts![]()
说明:127.0.0.1后面的横杠,和::1后面的横杠,就是ORS
OFS:
保存的是输出字段的分隔符(列分隔符),默认为空格
awk -v OFS="-" '{print $1,$2}' /tmp/hosts #以"-"作为字段分隔符awk -v OFS="\t" '{print $1,$2}' /tmp/hosts #以Tab制表符为字段分隔符awk -v OFS=". " '{print NR,$0}' /tmp/hosts #在每行前面加上行号和点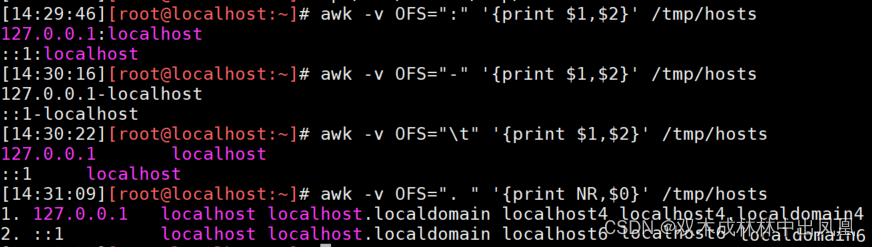
2.7.print指令
可以输出常量和变量,如果是字符串常量需要用双引号括起来,数字常量可以直接打印
awk '{print 123}' /tmp/hostsawk '{print "IP:",$1}' /tmp/hostsawk '{print "第1列:"$1,"\t第2列:"$2}' /tmp/hosts
2.8.条件匹配
awk支持使用正则进行模糊匹配,也支持字符串和数字的精确匹配,并且支持逻辑与和逻辑或。
| 比较符号 | 描述 |
| // | 全行数据正则匹配 |
| !// | 对全行数据正则匹配后取反 |
| ~// | 对特定数据正则匹配 |
| !~// | 对特定数据正则匹配后取反 |
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| >= | 大于等于 |
| 小于 | |
| 小于等于 | |
| && | 逻辑与,如A&&B,要求满足A并且满足B |
| || | 逻辑或,如AlB,要求满足A或者满足B |
示例代码:
awk '/localhost/' /tmp/hostsawk '$3~/local/' /tmp/hosts #每行的第3列去匹配localawk '$3~/local/{print $1,$2}' /tmp/hostsawk '$2=="localhost"' /tmp/hosts #第2列精确匹配localhostawk '$2!="localhost"' /tmp/hosts #取反awk -F: '$3<=10' /etc/passwd #第3列小于等于10的行awk -F: 'NR==10' /etc/passwd #仅显示第10行awk -F: '$3>1 && $3<5' /etc/passwd #逻辑与awk -F: '$3==1 || $3==5' /etc/passwd #逻辑或2.9.BEGIN和END
BEGIN导致动作指令仅在读取任何数据记录之前执行一次,END导致动作指令仅在读取完所有数据记录后执行一次
使用建议:BEGIN可以进行数据初始化,END可以进行数据汇总
示例代码1:
awk 'BEGIN{print "OK"}'awk 'END{print NR}' /etc/passwd #打印最后一行的行号上面代码的结果:

示例代码2:
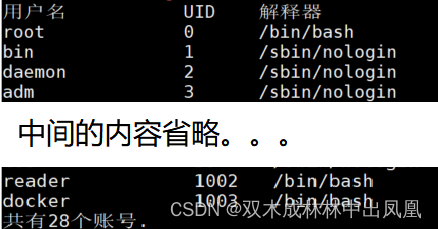
awk -F: 'BEGIN{print "用户名 UID 解释器"} \{print $1,$3,$7} \END {print "共有"NR"个账号."}' /etc/passwd | column -t #column实现格式化输出,并按升序排序上面代码的结果:
2.10.数字计算
示例代码:
[15:30:04][root@localhost:~]# awk 'BEGIN{print 2+3}'5[15:30:13][root@localhost:~]# awk 'BEGIN{print 2*3}'6[15:30:17][root@localhost:~]# awk 'BEGIN{print 2/5}'0.4[15:30:31][root@localhost:~]# awk 'BEGIN{print 5%2}'1[15:30:45][root@localhost:~]# awk 'BEGIN{print 5**2}'25[15:30:52][root@localhost:~]# awk 'BEGIN{x=5;y=2;print x-y}'3[15:31:27][root@localhost:~]# awk 'BEGIN{x=1;x++;print x}'2[15:31:46][root@localhost:~]# awk 'BEGIN{x=1;x+=1;print x}'2awk中变量【不需定义】就可以直接使用,作为字符处理时未定义的变量默认值为【空】,作为数字处理时未定义的变量默认值为【0】
awk 'BEGIN{print "["x"]","["y"]"}' # x和y默认为空awk 'BEGIN{print x+8}' # x默认为0上面代码的结果:

循环计数
示例代码1:
awk '/bash$/{x++} END{print x}' /etc/passwd上面代码说明:逐行读取/etc/passwd文件,【x初始值为0】,匹配到【以bash结尾】的行时自加1,最后打印x的值。
此处表明【以bash结尾】的行共有5行
![]()
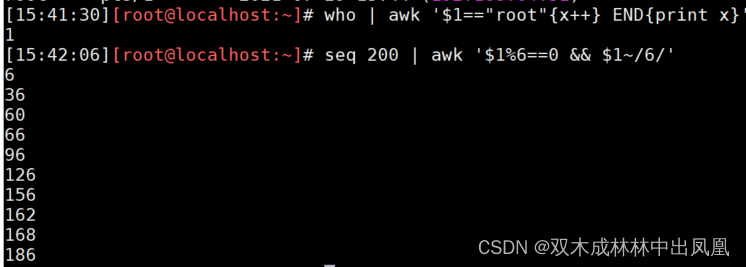
示例代码2:
who | awk '$1=="root"{x++} END{print x}' #统计有多少个客户端登录rootseq 200 | awk '$1%6==0 && $1~/6/' #打印1~200之间能被6整除且包含数字6的整数数字上面代码运行结果:
三、awk条件判断
if判断后面如果只有一个动作指令,则花括号{}可省略,如果if判断后面的指令为多条指令则需要使用花括号括起来,多个指令使用分号分隔。
3.1.单分支语句
语法:
if(判断条件){ 动作指令序列;}例子:
查找cpu使用率大于0.5的进程,代码如下:
ps -eo user,pid,pcpu,comm | awk '{if($3>0.5) print}'上面代码运行结果:

3.2.双分支if语句
语法:
if(判断条件){ 动作指令1;} else { 动作指令2;}例子:
统计系统用户与普通用户的个数,代码如下:
awk -F: '{if($3<1000){x++} else{y++}} END{print "系统用户个数:"x"","普通用户个数:"y""}' /etc/passwd代码运行结果如下:
![]()
3.3.多分支语句
语法如下
if(判断条件){ 动作指令1;} else if(判断条件2){ 动作指令2;} else { 动作指令N;}四、awk数组与循环
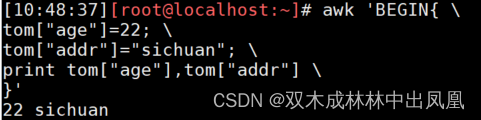
示例代码如下:
awk 'BEGIN{a[0]=11;a[1]=12;print a[0],a[1]}'awk 'BEGIN{ tom["age"]=22; tom["addr"]="sichuan"; print tom["age"],tom["addr"] }'上面代码的结果:
4.1.遍历数组
语法如下:
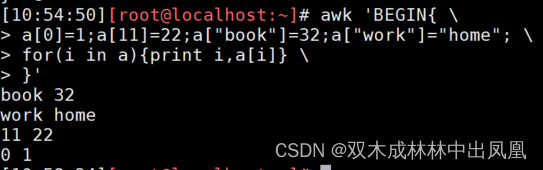
for(变量 in 数组名){ 动作指令序列}示例代码:
awk 'BEGIN{ \ a[0]=1;a[11]=22;a["book"]=32;a["work"]="home"; for(i in a){print i,a[i]} }'上面代码的运行结果:
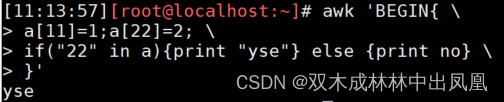
成员关系判断的方法,需要使用in,如下代码所示:
awk 'BEGIN{ \> a[11]=1;a[22]=2; \> if("22" in a){print "yse"} else {print no} \> }'上面代码的运行结果:
4.2.for循环
采用与C语言一样的语法格式,语法如下:
for(表达式1;表达式2;表达式3) { 动作指令序列}示例代码:
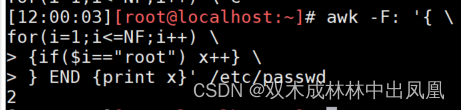
awk 'BEGIN{ for (i=1;i<=4;i++) {print i}}' awk -F: '{ \for(i=1;i<=NF;i++) \> {if($i=="root") x++} \> } END {print x}' /etc/passwd上面代码的说明:
统计root出现的次数。
这里面包含了【两个循环】,一个是隐含循环,awk会逐行处理数据;一个是for循环每列的值,如果等于root,就让x自加1,最后打印x的值。
上面代码的运行结果:
4.3.while循环
语法如下:
while(条件判断){ 动作指令序列;}示例代码如下:
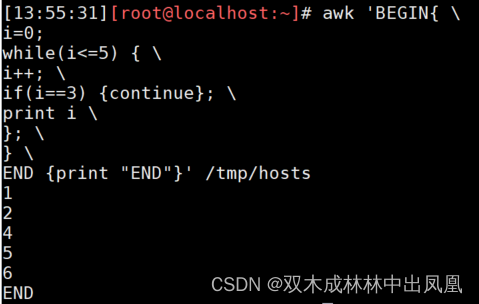
awk 'BEGIN{ i=1; while(i<=5) {print i;i++}}'4.4.中断语句
与shell类似,awk提供了【continue】、【break】、【exit】循环中断语句。
示例代码:
awk 'BEGIN{ \i=0;while(i<=5) { \i++; \if(i==3) {continue}; \print i \}; \} \END {print "END"}' /tmp/hosts上面代码的运行结果:
五、awk函数
5.1.内置I/O函数
getline函数:
能让awk立刻读取下一行数据(读取下一条记录并复制给$0, 并重新设置NF、NR和FNR)
示例代码如下:
#解决挂载逻辑卷时,分区信息跨行显示的问题df -h | awk '{if(NF==1) {getline;print $3}; if(NF==6) {print $4}}'next函数:
停止处理当前的输入记录,立刻读取下一条记录并返回awk程序的第一个模式匹配重新处理数据。
有点类似于循环语句中的continue,不会执行当次循环的后续语句。
getline和next的区别,代码如下:
awk -F: '/root/{getline;print "next line:",$0} {print "normal line"}' /etc/passwd上面代码的结果:

使用next:
awk -F: '/root/{next;print "next line:",$0} {print "normal line"}' /etc/passwd上面代码的运行结果:

结果分析:
经比较可以看出,getline,会继续执行后续的指令print “next line:”,而next不会执行后续指令,而是重新开始匹配。
system(命令)函数
可以直接在awk中调用shell命令,会启动一个【新shell进程】执行命令
示例代码:
awk 'BEGIN{system("ls")}'awk '{system("echo date:"$0)}' /tmp/hosts上面代码的运行结果:

5.2.内置数值函数
cos(expr)、sin(expr)、sqrt(expr)
int(expr)函数
可以对小数取整
[14:23:42][root@localhost:~]# awk 'BEGIN{print int(6.8)}'上面代码的结果:6
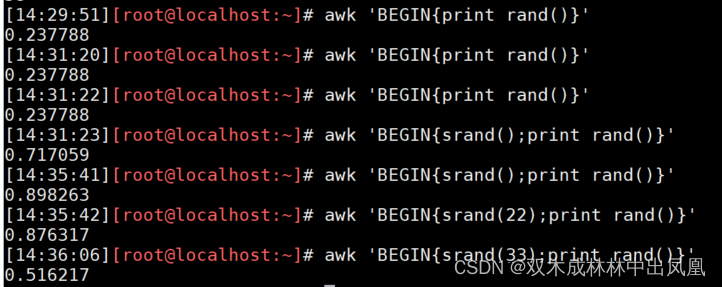
rand()函数
返回【0到1之间】的随机数,代码如下:
awk 'BEGIN{print rand()}'awk 'BEGIN{for(i=1;i<=5;i++) print int(100*rand())}' #生成5个100以内的随机数上面代码的结果:

srand([expr])
可以使用expr定义新的随机数种子,没有expr时则使用当前系统的时间为随机数种子
awk 'BEGIN{srand();print rand()}' #使用时间做随机数种子 awk 'BEGIN{srand(22);print rand()}' #使用数值做随机数种子代码运行结果:
5.3.内置字符串函数
length([s])函数
可以统计字符串s的长度,如果不指定字符串s则统计$0的长度
awk 'BEGIN{test="hello"; print length(test)}' #打印字符串长度awk 'BEGIN{t[0]="hi";t[1]="the"; print length(t)}' #返回数组元素个数awk '{print length()}' /etc/shells #返回文件每行的字符长度代码运行结果:

index(字符串1,字符串2)
返回字符串2在字符串1中的位置
awk 'BEGIN{test="hello";print index(test,"l")}'代码运行结果:
![]()
match(s,r)
根据正则表达式r返回其在字符串s中的位置坐标
[14:47:52][root@localhost:~]# awk 'BEGIN{print match("How much","[a-z]")}' #小写字母在第2个位置开始出现上面代码运行结果:2
tolower(srt)
可以将字符串转换为小写
[14:49:51][root@localhost:~]# awk 'BEGIN{print tolower("HELLo")}'上面代码运行结果:hello
toupper(str)
将字符串转为大写
split(字符串,数组,分隔符)
将字符串按特定的分隔符切片后存储在数组中,如果没指定分隔符,则使用IFS定义的。
数组下标从1开始
awk 'BEGIN{split("hello world",test); print test[1],test[2]}'awk 'BEGIN{split("hello:world",test,":"); print test[1],test[2]}' #指定冒号(:)为分隔符上面代码的运行结果:

gsub(r,s,[,t])
将字符串t中所有与正则表达式r匹配的字符串全部替换为s,如果没有指定字符串t,则默认对$0进行替换操作
[15:11:47][root@localhost:~]# head -1 /etc/passwd | awk '{gsub("[0-9]","");print $0}'上面代码运行结果:
root:x::**:root:/root:/bin/bashsub(r,s,[,t])
与gsub类似,但仅替换第一个匹配的字符串,而不是替换全部
substr(s,i,[,n])
对字符串s进行截取,从第i位开始,截取n个字符串,如果n没有指定则一直截取到字符串s的末尾位置
示例代码:
[15:16:17][root@localhost:~]# awk 'BEGIN{hi="Hello World"; print substr(hi,2,3)}' #从第2位开始截取3个字符上面代码运行结果:
ell5.4.内置时间函数
systime()
返回当前时间距离1970-01-01 00:00:00有多少秒
[15:16:21][root@localhost:~]# awk 'BEGIN{print systime()}'上面代码运行结果:
16278023285.5.用户自定义函数
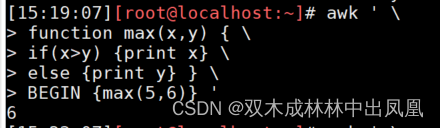
语法代码如下:
function 函数名(参数列表) { 命令序列 }示例代码:
awk ' \function max(x,y) { \if(x>y) {print x} \else {print y} } \BEGIN {max(5,6)} '代码运行结果:
六、常用命令
示例代码如下:
cat example.txt | awk 'NR%2==1' #删除example.txt文件中的所有偶数行echo " false" |awk -F' ' '{print $NF}' #去掉前面的空格docker images | grep 'mysql' | awk '{printf"%s:%s\n",$1,$2}' #获取镜像名:Tagps -ef | grep java | grep -v 'color' awk '{for (i=8;i<=NF;i++)printf("%s ", $i);print ""}' #获取从第八列开始到最后一列的内容七、场景例子
例子1:
假设有这么一个文件(学生成绩表):
$ cat score.txtMarry 2143 78 84 77Jack 2321 66 78 45Tom 2122 48 77 71Mike 2537 87 97 95Bob 2415 40 57 62awk脚本如下:
$ cat cal.awk#!/bin/awk -f#运行前BEGIN {math = 0english = 0computer = 0printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"printf "---------------------------------------------\n"}#运行中{math+=$3english+=$4computer+=$5printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5}#运行后END {printf "---------------------------------------------\n"printf " TOTAL:%10d %8d %8d \n", math, english, computerprintf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR}上面代码运行结果:
$ awk -f cal.awk score.txtNAME NO. MATH ENGLISH COMPUTER TOTAL---------------------------------------------Marry 2143 78 84 77 239Jack 2321 66 78 45 189Tom 2122 48 77 71 196Mike 2537 87 97 95 279Bob 2415 40 57 62 159--------------------------------------------- TOTAL: 319 393 350AVERAGE: 63.80 78.60 70.00例子2:
打印九九乘法表
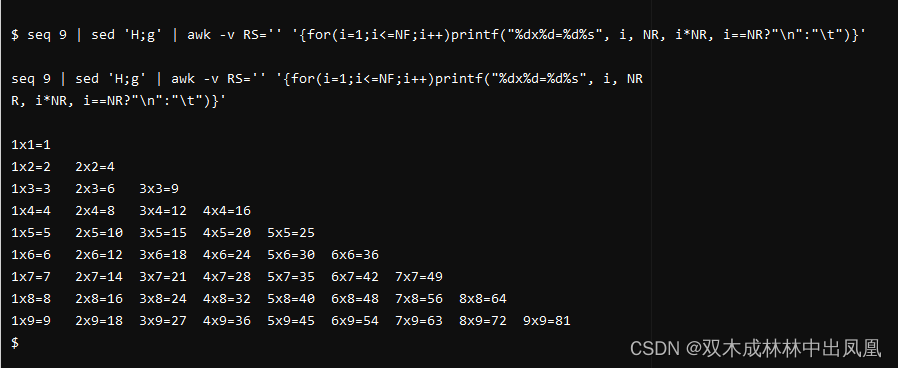
例子3:
判断进程是否存在,若存在则杀死进程
例如查找nginx进程是否存在:
ps -ef | grep "nginx" | grep -v grep | awk 'NR==1{print $2}' | xargs kill -9 >/dev/null 2>&1若能搜索到多个进程ID,去掉NR==1:
ps -ef | grep "nginx" | grep -v grep | awk '{print $2}' | xargs kill -9 >/dev/null 2>&1例子4:
针对输出结果为多行的命令获取指定字段:
例如获取当前机器可用内存(M):
free -m | awk 'NR==2{print $3}'代码运行结果:

例子5:
例如获取机器上安装的java版本:
java -version 2>&1 | awk 'NR==1{gsub(/"/,""); print $3}'
八、最后注意点:
虽然可以通过$0作用当前行,但awk命令中涉及下标的都是从1开始
awk不会对处理文本的内容做修改
所有awk内置方法名均为小写
length、sub、gsub三个方法都可以省略最后一个参数,作用于当前行,相当于$0,比如length()的输出等同于length($0)
#############################################################################
鸣谢:特别感谢所有在CSDN等网站热爱技术、乐于分享的工程师们。
说明:本文只是个人学习之用。
#############################################################################
来源地址:https://blog.csdn.net/zhangpchina/article/details/130551626







