
这篇文章主要讲解了“Python正则表达式的使用方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python正则表达式的使用方法是什么”吧!
什么是正则表达式?
简而言之,正则表达式(regex)用于探索给定字符串中的固定模式。
我们想找到的模式可以是任何东西。
可以创建类似于查找电子邮件或手机号码的模式。还可以创建查找以a开头、以z结尾的字符串的模式。
在上面的例子中:
import re pattern = r'[,;.,–]' print(len(re.findall(pattern,string)))我们想找出的模式是 r’[,;.,–]’。这个模式可找出想要的4个字符中的任何一个。regex101是一个用于测试模式的工具。将模式应用到目标字符串时,呈现出以下界面。
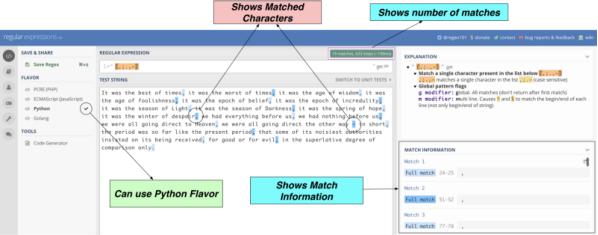
如图所示,可以在目标字符串中根据需要找到,;.,–。
每当需要测试正则表达式时,都会用到上面的工具。这比一次又一次运行python要快得多,调试也容易得多。
现在我们已经可以在目标字符串中找到这些模式,那么如何真正创建这些模式呢?
创建模式
使用正则表达式时,首先需要学习的是如何创建模式。
接下来将对一些最常用的模式进行逐一介绍。
可以想到最简单的模式是一个简单的字符串。
pattern = r'times' string = "It was the best of times, it was the worst of times." print(len(re.findall(pattern,string)))但这并不是很有用。为了帮助创建复杂的模式,正则表达式提供了特殊的字符/操作符。下面来逐个看看这些操作符。请等待gif加载。
1.[]操作符
这在第一个例子中使用过,可用于找到符合这些方括号中条件的一个字符。
[abc]-将查找文本中出现的所有a、b或c
[a-z]-将查找文本中出现的所有从a到z的字母
[a-z0–9A-Z]-将查找文本中出现的所有从A到Z的大写字母、从a到z的小写字母和从0到9的数字。
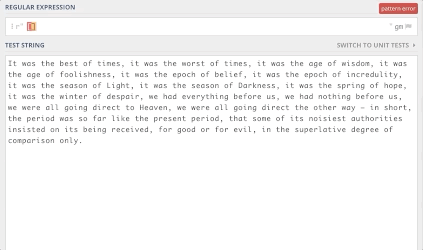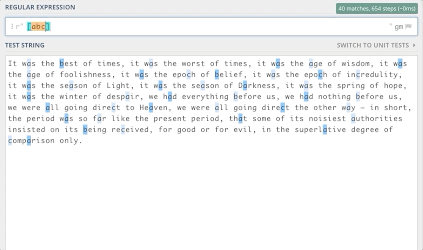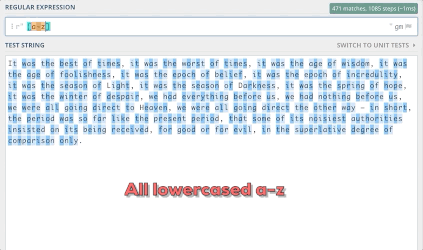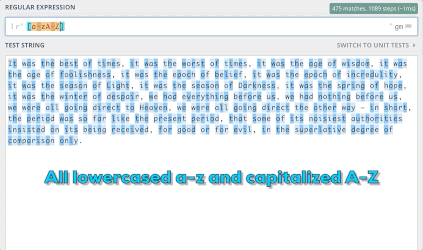
可以很容易地在Python中运行下列代码:
pattern = r'[a-zA-Z]' string = "It was the best of times, it was the worst of times." print(len(re.findall(pattern,string)))除了.findall,正则表达式还有很多其他功能,稍后会涉及到。
2.点算符
点运算符(.) 用于匹配除换行符以外的任何字符。
运算符最大的优点是,它们可以结合使用。
例如,想在字符串中找出以小d或大写D开头,以字母e结尾,包含6个字母的子字符串。
3.一些元序列
在使用正则表达式时,一些模式会经常被用到。因此正则表达式为这些模式创建了一些快捷方式。最常用的快捷方式如下:
\w,匹配任何字母、数字或下划线。相当于[a-zA-Z0–9_]
\W,匹配除字母、数字或下划线以外的任何内容。
\d,匹配任何十进制数字。相当于[0–9]。
\D,匹配除十进制数字以外的任何数字。
4.加号和星形运算符
点算符只是用于获取任何字符的单个实例。如果想找出更多实例要怎么做呢?
加号+用于表示最左边字符的一个或多个实例。
星号*用于表示最左边字符的0个或多个实例。
例如,如果想找出所有以d开头,以e结尾的子字符串,d和e之间可以没有也可以有多个字符。我们可以用:d\w*e
如果想找出所有以d开头,以e结尾的子字符串,在d和e之间至少有一个字符,我们可以用:d\w+e
还可以使用更为通用的方法:用{}
\w{n} - 重复\w 正好n次。
\w{n,} - 重复\w至少n次,或者更多次。
\w{n1, n2} - 重复 \w 至少n1次,但不超过n2次。
5.^插入符号和$美元符号。
^插入符号匹配字符串的开始,而$美元符号则匹配字符串的结尾。
6.单词边界
这是一个重要的概念。
有没有注意到,在上面的例子中,总是匹配子字符串,而不是匹配单词?
如果想找出所有以d开头的单词呢?
可以使用d\w*模式吗?下面用网络工具来试一试吧。
正则表达式函数
目前为止,只使用了 re包中的findall 函数,其实还有很多其他函数。下面来逐个介绍。
1. findall
上面已经使用了 findall。这是我最常使用的一个。下面来正式认识一下这个函数吧。
输入:模式和测试字符串
输出:字符串列表。
#USAGE: pattern = r'[iI]t' string = "It was the best of times, it was the worst of times." matches = re.findall(pattern,string) for match in matches: print(match)------------------------------------------------------------ It it2.搜索
输入:模式和测试字符串
输出:首次匹配的位置对象。
#USAGE: pattern = r'[iI]t' string = "It was the best of times, it was the worst of times." location = re.search(pattern,string) print(location) ------------------------------------------------------------ <_sre.SRE_Match object; span=(0, 2), match='It'>可以使用下面编程获取该位置对象的数据:
print(location.group()) ------------------------------------------------------------ 'It'3.替换
这个功能也很重要。当使用自然语言处理程序时,有时需要用X替换整数,或者可能需要编辑一些文件。任何文本编辑器中的查找和替换都可以做到。
输入:搜索模式、替换模式和目标字符串
输出:替换字符串
string = "It was the best of times, it was the worst of times."
string = re.sub(r'times', r'life', string)
print(string)
------------------------------------------------------------
It was the best of life, it was the worst of life.
案例研究
正则表达式在许多需要验证的情况下都会用到。我们可能会在网站上看到类似这样的提示:“这不是有效的电子邮件地址”。虽然可以使用多个if和else条件来编写这样的提示,但正则表达式可能更具优势。
1.PAN编号
在美国,SSN(社会安全号码)是用于税务识别的号码,而在印度,税务识别用的则是 PAN号码。PAN的基本验证标准是:上面所有的字母都必须大写,字符的顺序如下:
那么问题是:
“ABcDE1234L”是有效的PAN号码吗?
如果没有正则表达式,该如何回答这个问题呢?可能会编写一个for循环,并进行遍历搜索。但如果用正则表达式,那就像下面这样简单:
match=re.search(r’[A-Z]{5}[0–9]{4}[A-Z]’,'ABcDE1234L') if match: print(True) else: print(False) ----------------------------------------------------------------- False2.查找域名
有时我们必须从一个庞大的文本文档中找出电话号码、电子邮件地址或域名等。
例如,假设有以下文本:
<div class="reflist" style="list-style-type: decimal;"> <ol class="references"> <li id="cite_note-1"><span class="mw-cite-backlink"><b>^ ["Train (noun)"](http://www.askoxford.com/concise_oed/train?view=uk). <i>(definition – Compact OED)</i>. Oxford University Press<span class="reference-accessdate">. Retrieved 2008-03-18</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Train+%28noun%29&rft.genre=article&rft_id=http%3A%2F%2Fwww.askoxford.com%2Fconcise_oed%2Ftrain%3Fview%3Duk&rft.jtitle=%28definition+%E2%80%93+Compact+OED%29&rft.pub=Oxford+University+Press&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li> <li id="cite_note-2"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Atchison, Topeka and Santa Fe Railway (1948). <i>Rules: Operating Department</i>. p. 7.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.aulast=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.btitle=Rules%3A+Operating+Department&rft.date=1948&rft.genre=book&rft.pages=7&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li> <li id="cite_note-3"><span class="mw-cite-backlink"><b>^ [Hydrogen trains](http://www.hydrogencarsnow.com/blog2/index.php/hydrogen-vehicles/i-hear-the-hydrogen-train-a-comin-its-rolling-round-the-bend/)</span></li> <li id="cite_note-4"><span class="mw-cite-backlink"><b>^ [Vehicle Projects Inc. Fuel cell locomotive](http://www.bnsf.com/media/news/articles/2008/01/2008-01-09a.html)</span></li> <li id="cite_note-5"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Central Japan Railway (2006). <i>Central Japan Railway Data Book 2006</i>. p. 16.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Central+Japan+Railway&rft.aulast=Central+Japan+Railway&rft.btitle=Central+Japan+Railway+Data+Book+2006&rft.date=2006&rft.genre=book&rft.pages=16&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li> <li id="cite_note-6"><span class="mw-cite-backlink"><b>^ ["Overview Of the existing Mumbai Suburban Railway"](http://web.archive.org/web/20080620033027/http://www.mrvc.indianrail.gov.in/overview.htm). _Official webpage of Mumbai Railway Vikas Corporation_. Archived from [the original](http://www.mrvc.indianrail.gov.in/overview.htm) on 2008-06-20<span class="reference-accessdate">. Retrieved 2008-12-11</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Overview+Of+the+existing+Mumbai+Suburban+Railway&rft.genre=article&rft_id=http%3A%2F%2Fwww.mrvc.indianrail.gov.in%2Foverview.htm&rft.jtitle=Official+webpage+of+Mumbai+Railway+Vikas+Corporation&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li> </ol> </div>需要从上面文本中找出这里所有的域名—— askoxford.com;bnsf.com;hydrogencarsnow.com;mrvc.indianrail.gov.in;web.archive.org
该怎么做?
match=re.findall(r'http(s:|:)\/\/(www.|ww2.|)([0-9a-z.A-Z-]*\.\w{2,3})',string) for elem in match: print(elem) -------------------------------------------------------------------- (':', 'www.', 'askoxford.com') (':', 'www.', 'hydrogencarsnow.com') (':', 'www.', 'bnsf.com') (':', '', 'web.archive.org') (':', 'www.', 'mrvc.indianrail.gov.in') (':', 'www.', 'mrvc.indianrail.gov.in')这里用到了or运算符,match返回元组,保留()里的模式部分。
3.查找电子邮件地址:
下面的正则表达式用于在长文本中查找电子邮件地址。
match=re.findall(r'([\w0-9-._]+@[\w0-9-.]+[\w0-9]{2,3})',string)这些都是高级示例,提供的信息已经足够帮你理解这些示例了。
感谢各位的阅读,以上就是“Python正则表达式的使用方法是什么”的内容了,经过本文的学习后,相信大家对Python正则表达式的使用方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!











