
本人大二,因为Python结业考试项目,又想要学习机器学习方向,但是由于接触时间不长,选择了实验楼的Python破解验证码这个项目作为我的项目,
我在原来的基础上加了一些代码用于完善,并且对功能如何实现记录在此,第一次接触到图像识别的项目。
这是项目需要的文件链接:https://pan.baidu.com/s/1qoJ5qvU9idmH0v7dnFkMCw
总体思想是将验证码变成黑白,然后切割成单字符,再与准备好的训练集相互比对,将相似度最高的字符输出。
第一步,先对一个验证码进行处理, ,①目标是将图片尽量简化成黑白,②然后切割出单字符,对此使用的是PIL的Image库。
,①目标是将图片尽量简化成黑白,②然后切割出单字符,对此使用的是PIL的Image库。
①导入图片,转换成8位像素的图片
#加载图片并且转换成8位像素
im = Image.open("./captcha.gif")
im.convert("P")我们需要知道验证码的颜色,拾色器工具是一种方法,但是我们通过数据说话,通过打印直方图 print(im.histogram()) 可以返回如下列表
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 1, 0, 0, 1, 0, 2, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 1, 3, 3, 0, 0, 0, 0, 0, 0, 1, 0, 3, 2, 132, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 15, 0, 1, 0, 1, 0, 0, 8, 1, 0, 0, 0, 0, 1, 6, 0, 2, 0, 0, 0, 0, 18, 1, 1, 1, 1, 1, 2, 365, 115, 0, 1, 0, 0, 0, 135, 186, 0, 0, 1, 0, 0, 0, 116, 3, 0, 0, 0, 0, 0, 21, 1, 1, 0, 0, 0, 2, 10, 2, 0, 0, 0, 0, 2, 10, 0, 0, 0, 0, 1, 0, 625]列表每一个元素代表在图片中含有对应位的颜色的像素的数量。(白色255,黑色是0)
接下来进行排序
his = im.histogram()
values = {}
#将颜色作为键,出现次数作为值,形成字典
for i in range(256):
values[i] = his[i]
#对字典进行排序,排序根据字典的值(x[0]是字典的键),从大到小排序
for j,k in sorted(values.items(),key=lambda x:x[1],reverse = True)[:10]:
print(j,k)即可得到以下
255 625
212 365
220 186
219 135
169 132
227 116
213 115
234 21
205 18
184 15220与227是我们所需要的红色,于是我们可以创建一个相同大小的纯白色的图片,将符合的颜色变为黑色0
(其实这里也就表现了这个程序的第一个局限性,颜色要人为判断,并且每一个字符都要颜色统一)
# 构造一个纯白的等大小的图片im2
im2 = Image.new("P", im.size, 255)
#遍历加载的图片,对每个像素点判断是否符合要求
for x in range(im.size[1]): #im.size[1]是垂直像素数
for y in range(im.size[0]): #im.size[0]是水平像素数
pix = im.getpixel((y, x)) #获取每一个像素点的颜色纸
if pix == 220 or pix == 227: #判断是否符合220或者227
im2.putpixel((y, x), 0) #符合则变成黑色 之后用im2.show(),可以看到这个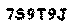 很符合我们的想法
很符合我们的想法
②然后我们需要切割出单个字符,实验楼里面说:“由于例子比较简单,我们对其进行纵向切割:”,恕我刚刚接触时间不长,还不太能了解这句话后面的深度
具体做法就是纵向从左到右“一刀刀往下切”
一个变量判断是否切到了黑色的像素点,切到则转换“刀”为切到字符的状态并且记录当前的水平位置,
如果没有切到黑色像素点,但是“刀”依旧是切到字符的状态,则重置“刀”为未切到字符的状态并且当前的记录水平位置,
第一次记录的位置到第二次记录的位置一定有一个字符。
inletter = False #判断是否切割到了字符
foundletter = False #未切到字符的状态记录
start = 0 #记录开始的x值
end = 0 #记录结束的x值
letters = [] #记录切割到的字符
#纵向切割记录数据
for x in range(im2.size[0]): #遍历水平的像素点
for y in range(im2.size[1]): #同一水平值下遍历垂直的(用刀切)
pix = im2.getpixel((x, y)) #获取像素点颜色
if pix != 255: #碰到黑色就位切到了
inletter = True
# 切到但是刀的状态是没有切到,则转换刀的状态为切到
if foundletter == False and inletter == True:
foundletter = True
start = x
#如果上面if没有成立,则下面的if不会发生,所以letters一定会记录到2个不同的值
#没有切到但是刀的状态是切到了,则转换刀的状态为未切到
if foundletter == True and inletter == False:
foundletter = False
end = x
letters.append((start, end))
#重置为未切到字符
inletter = False打印letters,符合预期
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]然后将记录到的数据,对图片进行切割
#切割字符
for letter in letters:
#参数一个四元组,四个元素依次是左上角的x和y值与右下角的x和y值
im3 = im2.crop((letter[0], 0, letter[1], im.size[1])) 然后可以遍历保存im3为.gif格式,可以得到6个图片




 都是单独的字符了,至此第一步完成
都是单独的字符了,至此第一步完成
接下来就是核心的第二步,怎么把每一个字符输出对应的数字?
首先是实验楼给出的论文网站http://ondoc.logand.com/d/2697/pdf,
“也说了这个这个方法的优缺点:
- 不需要大量的训练迭代
- 不会训练过度
- 你可以随时加入/移除错误的数据查看效果
- 很容易理解和编写成代码
- 提供分级结果,你可以查看最接近的多个匹配
- 对于无法识别的东西只要加入到搜索引擎中,马上就能识别了。
当然它也有缺点,例如分类的速度比神经网络慢很多,它不能找到自己的方法解决问题等等。”
然后实验楼只是简单的介绍了一下原理,并未详细说明,为此我通读了整篇论文,来说说我的一点理解。
有1篇讲猫和狗和鼠的文章,但是我想知道这篇文章主要讲的是哪个动物,为此我将“猫”,“狗”,“鼠”这几个特征性的单词作为我的重点关注对象,并建立一个一个三维空间,x轴对应“猫”这个单词出现的次数,同理y轴对应“狗”,z轴对应“鼠”。首先先用于第一篇文章,“猫”出现一次,x就加1,“狗”出现一次,y就加1,“鼠”出现一次,z就加1,那么整篇文章遍历完了,就一定在三维空间中有一个向量(x1,y1,z1)对应出现次数,然后将这个向量投影在x,y,z轴的值,最大的值对应的轴就是这篇文章出现最多的单词了,也应该是这篇文章主要讲的动物了。
在x轴上的投影为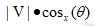 在向量大小为定值时,夹角越小,余弦越大,则投影越大,所以我们不用计算出具体的投影的值,问题转化成了求夹角的余弦即可。
在向量大小为定值时,夹角越小,余弦越大,则投影越大,所以我们不用计算出具体的投影的值,问题转化成了求夹角的余弦即可。
两向量的夹角公式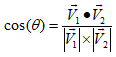 带入相应的数值即可得到
带入相应的数值即可得到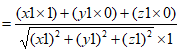 即可知道和x轴夹角,同理与y轴夹角
即可知道和x轴夹角,同理与y轴夹角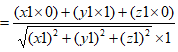 与z轴夹角
与z轴夹角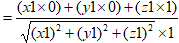 之后只需要找出最大的余弦值,对应的字符就是最相关的。
之后只需要找出最大的余弦值,对应的字符就是最相关的。
这是基本矢量空间搜索引擎理论的含义,然后将这个方法用于图片,会变得更加的复杂,但是核心思想并未改变。
然后我们照着改一下。
有1个未知字符(字母或者数字)的图片,但是我想知道这个字符讲的是哪个字符,为此我找了26+10个对应不同字符的图片作为我的已知的标准,将标准图片的每个像素点的颜色作为我的重点关注对象,再并建立一个n维向量,每一维则对应一个标准图片的像素点位置,我只要把未知图片每一个像素点的颜色值值代入,以及标准图片每一个像素点的颜色值代入,最后一定有2个向量表示未知图片和这一个标准图片,然后求未知图片与这一标准图片的向量的夹角的余弦值,然后用同样方法做36遍,再按照相似度从大到小排序即可,最大余弦值的对应的已知字符应该最接近。这有个要求就是我们的标准的像素点的数量和未知的图片像素点数量要想接近,这应该涉及到了数据预处理的问题,我还没有学,但是我觉得如果像素点数量差距变大,会很影响判断的,所以以下,我们当我们的数据都很好的预处理了。
总的来说,和原本的区别就是我们的重点关注对象变多了,以及我们的标准也不只是单单的坐标轴了,标准也变成一个向量。综上我们一共需要完成①图片变成矢量②计算矢量大小③计算夹角
①图片准换成矢量,我们定义成为一个函数,返回一个字典,键就是像素点位置(0,1,2,3...),值就是像素点颜色(0,255)
#图片转换成矢量,字典化图片
def buildvector(im):#参数是字符的图片
d1 = {} #字典记录像素点位置和对应的颜色
count =0 #用来增加像素点位置
for i in im.getdata(): #i就是从0开始对应的颜色值
d1[count] = i #把颜色值作为值加入字典
count +=1
return d1 #返回{像素点位置:颜色}的字典②计算矢量大小以及③计算夹角同时放在一个类里面
import math
#比较矢量相似度的类
class VectorCompare:
#计算矢量大小,即求余弦的分母的元素
def magnitude (self,concordance):
total = 0
for word,count in concordance.items():#word像素点位置,count对应的颜色(0或255)
total += count**2
return math.sqrt(total) #求出向量的模的大小
#计算矢量的夹角
def relation(self,concordance1,concordance2): #输入两个字典化图片
topvalue =0 #求余弦公式的分子
for word,count in concordance1.items(): #需要很好的数据预处理
if word in concordance2:
# 每一维度(像素点),两向量的颜色值(0或255)相乘,求出余弦公式分子
topvalue += count *concordance2[word]
all_magnitude = self.magnitude(concordance1)*self.magnitude(concordance2) #求余弦公式的分母
relevance = topvalue/all_magnitude #求出余弦
return relevance #返回相关性之后就是要用图片转换矢量函数先把我的标准训练集先完成,而标准训练集就是iconset文件夹下的文件,我们需要从iconset文件夹里把每一个图片和文件夹的名字一一对应上,所以我们需要用os库来获取文件名
#训练集名字
iconset = ['0','1','2','3','4','5','6','7','8','9',
'a','b','c','d','e','f','g','h','i','j',
'k','l','m','n','o','p','q','r','s','t',
'u','v','w','x','y','z']
#加载训练集
imageset = [] #[{正确名字1:[字典化图片]}, {正确名字2:[字典化图片]}, {正确名字3:[字典化图片]}。。。]
#字典化iconset里面图片
for letter in iconset: #遍历iconset所有要训练的名字
for img in os.listdir("./iconset/%s"%(letter)): #遍历所有iconset里面的文件夹
temp = [] #列表用来记录字典化图片
if img != "Thumbs.db" and img!= ".DS_Store": #不需要训练的文件
temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img)))) #生成字典化图片
imageset.append({letter:temp}) #将训练的名字和字典化图片再对应最后一步,把我们之前切的im3逐一遍历,再排序出相似度最高的对应的正确名字,最后打印出所有字符串
#判断单个字符的相似度
str = "" #打印字符串
for letter in letters:
im3 = im2.crop((letter[0], 0, letter[1], im.size[1]))
guess = [] #记录和所有训练集的数据,用来排序
for image in imageset: #和所有训练集的数据进行遍历
for x, y in image.items(): #x是正确名字,y是对应的[字典化图片]
if len(y) != 0: #y不为空,除去是Thumbs.db和.DS_Store训练出来的空列表
guess.append((v.relation(y[0], buildvector(im3)), x))#y[0]就是字典化图片
guess.sort(reverse=True) #从大到小排序
str += "{}".format(guess[0][1]) #相似度最高的字符加到字符串里
print(str) #打印打印结果为
7s9t9j这一个到此为止成功。实验楼的项目至此结束
所有代码
from PIL import Image
import math
import os
#比较矢量相似度的类
class VectorCompare:
#计算矢量大小,即求余弦的分母的元素
def magnitude (self,concordance):
total = 0
for word,count in concordance.items():#word像素点位置,count对应的颜色(0或255)
total += count**2
return math.sqrt(total) #求出向量的模的大小
#计算矢量的夹角
def relation(self,concordance1,concordance2): #输入两个字典化图片
topvalue =0 #求余弦公式的分子
for word,count in concordance1.items(): #需要很好的数据预处理
if word in concordance2:
# 同一维度(像素点),两向量的颜色值(0或255)相乘,求出余弦公式分子
topvalue += count *concordance2[word]
all_magnitude = self.magnitude(concordance1)*self.magnitude(concordance2) #求余弦公式的分母
relevance = topvalue/all_magnitude #求出余弦
return relevance #返回相关性
#图片转换成矢量,字典化图片
def buildvector(im):#参数是字符的图片
d1 = {} #字典记录像素点位置和对应的颜色
count =0 #用来增加像素点位置
for i in im.getdata(): #i就是从0开始对应的颜色值
d1[count] = i #把颜色值作为值加入字典
count +=1
return d1 #返回{像素点位置:颜色}的字典
#实例化
v = VectorCompare()
#训练集名字
iconset = ['0','1','2','3','4','5','6','7','8','9',
'a','b','c','d','e','f','g','h','i','j',
'k','l','m','n','o','p','q','r','s','t',
'u','v','w','x','y','z']
#加载训练集
imageset = [] #[{正确名字1:[字典化图片]}, {正确名字2:[字典化图片]}, {正确名字3:[字典化图片]}。。。]
#字典化iconset里面图片
for letter in iconset: #遍历iconset所有要训练的名字
for img in os.listdir("./iconset/%s"%(letter)): #遍历所有iconset里面的文件夹
temp = [] #列表用来记录字典化图片
if img != "Thumbs.db" and img!= ".DS_Store": #不需要训练的文件
temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img)))) #生成字典化图片
imageset.append({letter:temp}) #将训练的名字和字典化图片再对应
# 加载图片并且转换成8位像素
im = Image.open("./captcha.gif")
im.convert("P")
# 构造一个纯白的等大小的图片im2
im2 = Image.new("P", im.size, 255)
# 遍历加载的图片,对每个像素点判断是否符合要求
for x in range(im.size[1]): # im.size[1]是垂直像素数
for y in range(im.size[0]): # im.size[0]是水平像素数
pix = im.getpixel((y, x)) # 获取每一个像素点的颜色纸
if pix == 220 or pix == 227: # 判断是否符合220或者227
im2.putpixel((y, x), 0) # 符合则变成黑色
inletter = False # 判断是否切割到了字符
foundletter = False # 未切到字符的状态记录
start = 0 # 记录开始的x值
end = 0 # 记录结束的x值
letters = [] # 记录切割到的字符
# 纵向切割记录数据
for x in range(im2.size[0]): # 遍历水平的像素点
for y in range(im2.size[1]): # 同一水平值下遍历垂直的(用刀切)
pix = im2.getpixel((x, y)) # 获取像素点颜色
if pix != 255: # 碰到黑色就位切到了
inletter = True
# 切到但是刀的状态是没有切到,则转换刀的状态为切到
if foundletter == False and inletter == True:
foundletter = True
start = x
# 如果上面if没有成立,则下面的if不会发生,所以letters一定会记录到2个不同的值
# 没有切到但是刀的状态是切到了,则转换刀的状态为未切到
if foundletter == True and inletter == False:
foundletter = False
end = x
letters.append((start, end))
# 重置为未切到字符
inletter = False
# 判断单个字符的相似度
str = "" # 打印字符串
for letter in letters:
im3 = im2.crop((letter[0], 0, letter[1], im.size[1]))
guess = [] # 记录和所有训练集的数据,用来排序
for image in imageset: # 和所有训练集的数据进行遍历
for x, y in image.items(): # x是正确名字,y是对应的[字典化图片]
if len(y) != 0: # y不为空,除去是Thumbs.db和.DS_Store训练出来的空列表
guess.append((v.relation(y[0], buildvector(im3)), x)) # y[0]就是字典化图片
guess.sort(reverse=True) # 从大到小排序
str += "{}".format(guess[0][1]) # 相似度最高的字符加到字符串里
之后便要对所有的examples文件夹下的验证码都进行训练,看看准确度如何
从加载图片到最后的判断字符都放入一个for循环语句当中
for listname in os.listdir("./examples"):以及验证码图片的加载也要修改为
if listname != "Thumbs.db" and listname != ".DS_Store":
im = Image.open("./examples/%s" % (listname))
im.convert("P")下面的所有代码都要这个if条件下才能实施,全部再缩进一行
当我再次打印输出的时候显示的验证码结果是
0q1dp0
0q3tje
24alb0p
47j17b
4wwfa
5dwvo
5t0qh
75rc1qp
7s9t9j
bibfkf
bf5te
9f2luc
9tmxf
9to1tkp
akfvav
aro2hz
b17lzh
b3rk8h
b3ufl9
pbmk5jx
2mybt
cw0qy
cfyrg
eb0qy3
etg5z
fnt5x
phd0qli
ivusjv
jfte2
zttiq
k0qg4l
k6e2ir
w0qlk
w7k5z
l9felg
lz73a7
t1sge
n67dmb
nlrzo7
tmisv
f15jnd
fmiunq
qfwix9
r2lvkd
r6r12e
718ft
t6khw
ibrjc
puc1rdk
v63gde
7f54eg
xfnrsn有长有短,但是验证码的长度应当是6个字符,对错我也并不知晓,所以我开始着手准备
我在循环前加了一系列变量用来记录我所疑惑的
success =0 #记录正确匹配个数
fail = 0 #记录失败的个数
success_name_list=[] #记录正确匹配的名字
fail_name_list =[] #记录失败的名字
wrong_length_name = [] #记录失败的错误长度的名字
wrong_letter_count_dict= {} #记录失败的对应的字母错误并累加记录次数
correct_name_list = [] #记录错误所对应的正确名字,列表下标对应,对比容易然后我在每一次循环刚开始的时候都记录下当前验证码的正确名字,也就是图片名
correct_name = listname[:6] # 记录正确的文件名 ,用来判断是否正确然后就是对结果str进行判断,并记录相关数据
if str == correct_name: #正确
success += 1 #正确次数加1
success_name_list.append(str) #记录正确的名字
else:
fail +=1 #错误次数加1
fail_name_list.append(str) #记录错误名字
correct_name_list.append(correct_name) #同时记录对应的正确名字用来进一步分析最后就是将相关数据汇总分析,我尽我能力全分析了,过程具体注释也就不详细写了,
count =0 #错误名字列表和对应的正确名字的下标一一对应
#统计出错误的原因
for letters in fail_name_list:
# 长度不统一
if len(letters) != len(correct_name_list[count]):
wrong_length_name.append(letters)
count+=1
#长度统一,但是识别错误
else:
index =0
for letter in letters:
if letter != correct_name_list[count][index]:
wrong_letter_count_dict[letter] = wrong_letter_count_dict.get(letter,0)+1
index+=1
else:
index+=1
count+=1
success_rate = success/(success+fail) #成功率
#打印总数,成功和失败的数量,以及成功率
print("total count = {}\n"
"success = {}, failed = {} \n"
" success_rate = {}\n".format(success+fail,success,fail,success_rate))
#打印成功的验证码的名字
print("Success Trainning name:")
for i in range(len(success_name_list)):
print(success_name_list[i])
wrong_length_count = len(wrong_length_name) #去除长度识别错误的数量
success_rate = success/(success+fail-wrong_length_count) #去除长度错误的图片后的成功率
#打印错误长度的验证码的数量
print("\nWrong Length count:{}".format(wrong_length_count))
print("total count without wrong length= {}\n"
"success = {}, failed = without wrong length = {} \n"
"success_rate without wrong length= {:.4f}\n".format(success+fail-wrong_length_count,
success,
fail-wrong_length_count,
success_rate))
#将字母识别错误>1的输出,用来表示标准样本的错误
wrong_letter_count_list = sorted(wrong_letter_count_dict.items(),
key = lambda x:x[1],
reverse =True)
for letter in wrong_letter_count_list:
if letter[1] >1:
print("Need more {} to train".format(letter[0]))最后运行一下
total count = 52
success = 13, failed = 39
success_rate = 0.25
Success Trainning name:
0q3tje
47j17b
7s9t9j
9f2luc
b3rk8h
b3ufl9
k6e2ir
nlrzo7
qfwix9
r2lvkd
r6r12e
v63gde
xfnrsn
Wrong Length count:25
total count without wrong length= 27
success = 13, failed = without wrong length = 14
success_rate without wrong length= 0.4815
Need more f to train
Need more b to train
Need more v to train
Need more 7 to train其他的数据不多说,我后来打印了错误字符的字典,发现“f”错了4次我很好奇为什么,然后打开训练集一看

好嘛,根本没有小写“f”的训练集,网上的训练集也不靠谱啊
最后总体说说我有可能需要改进的地方,首先是之前说到的颜色,要我手动输入,而且还必须统一颜色,弄得不好还可能要多出一个字符,可是如果要解决这个要k邻近?或者涉及到神经网络了,我才刚看了一点书。。。路漫漫其修远兮。其次,根据上面的数据可以看到很多辨别失败的是因为长度辨识错误,也就是字符的像素点重合在一起了,会把两个字符合成一个字符判断,我现在想不到能用什么办法来解决这个问题。智商不够用。
真正的最后附上我的全部代码
from PIL import Image
import math
import os
#比较矢量相似度的类
class VectorCompare:
#计算矢量大小,即求余弦的分母的元素
def magnitude (self,concordance):
total = 0
for word,count in concordance.items():#word像素点位置,count对应的颜色(0或255)
total += count**2
return math.sqrt(total) #求出向量的模的大小
#计算矢量的夹角
def relation(self,concordance1,concordance2): #输入两个字典化图片
topvalue =0 #求余弦公式的分子
for word,count in concordance1.items(): #需要很好的数据预处理
if word in concordance2:
# 同一维度(像素点),两向量的颜色值(0或255)相乘,求出余弦公式分子
topvalue += count *concordance2[word]
all_magnitude = self.magnitude(concordance1)*self.magnitude(concordance2) #求余弦公式的分母
relevance = topvalue/all_magnitude #求出余弦
return relevance #返回相关性
#图片转换成矢量,字典化图片
def buildvector(im):#参数是字符的图片
d1 = {} #字典记录像素点位置和对应的颜色
count =0 #用来增加像素点位置
for i in im.getdata(): #i就是从0开始对应的颜色值
d1[count] = i #把颜色值作为值加入字典
count +=1
return d1 #返回{像素点位置:颜色}的字典
#实例化
v = VectorCompare()
#训练集名字
iconset = ['0','1','2','3','4','5','6','7','8','9',
'a','b','c','d','e','f','g','h','i','j',
'k','l','m','n','o','p','q','r','s','t',
'u','v','w','x','y','z']
#加载训练集
imageset = [] #[{正确名字1:[字典化图片]}, {正确名字2:[字典化图片]}, {正确名字3:[字典化图片]}。。。]
#字典化iconset里面图片
for letter in iconset: #遍历iconset所有要训练的名字
for img in os.listdir("./iconset/%s"%(letter)): #遍历所有iconset里面的文件夹
temp = [] #列表用来记录字典化图片
if img != "Thumbs.db" and img!= ".DS_Store": #不需要训练的文件
temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img)))) #生成字典化图片
imageset.append({letter:temp}) #将训练的名字和字典化图片再对应
success =0 #记录正确匹配个数
fail = 0 #记录失败的个数
success_name_list=[] #记录正确匹配的名字
fail_name_list =[] #记录失败的名字
wrong_length_name = [] #记录失败的错误长度的名字
wrong_letter_count_dict= {} #记录失败的对应的字母错误并累加记录次数
correct_name_list = [] #记录错误所对应的正确名字,列表下标对应对比容易
for listname in os.listdir("./examples"):
correct_name = listname[:6] # 记录正确的文件名 ,用来比较
# 加载图片并且转换成8位像素
if listname != "Thumbs.db" and listname != ".DS_Store":
im = Image.open("./examples/%s" % (listname))
im.convert("P")
# 构造一个纯白的等大小的图片im2
im2 = Image.new("P", im.size, 255)
# 遍历加载的图片,对每个像素点判断是否符合要求
for x in range(im.size[1]): # im.size[1]是垂直像素数
for y in range(im.size[0]): # im.size[0]是水平像素数
pix = im.getpixel((y, x)) # 获取每一个像素点的颜色纸
if pix == 220 or pix == 227: # 判断是否符合220或者227
im2.putpixel((y, x), 0) # 符合则变成黑色
inletter = False # 判断是否切割到了字符
foundletter = False # 未切到字符的状态记录
start = 0 # 记录开始的x值
end = 0 # 记录结束的x值
letters = [] # 记录切割到的字符
# 纵向切割记录数据
for x in range(im2.size[0]): # 遍历水平的像素点
for y in range(im2.size[1]): # 同一水平值下遍历垂直的(用刀切)
pix = im2.getpixel((x, y)) # 获取像素点颜色
if pix != 255: # 碰到黑色就位切到了
inletter = True
# 切到但是刀的状态是没有切到,则转换刀的状态为切到
if foundletter == False and inletter == True:
foundletter = True
start = x
# 如果上面if没有成立,则下面的if不会发生,所以letters一定会记录到2个不同的值
# 没有切到但是刀的状态是切到了,则转换刀的状态为未切到
if foundletter == True and inletter == False:
foundletter = False
end = x
letters.append((start, end))
# 重置为未切到字符
inletter = False
# 判断单个字符的相似度
str = "" # 打印字符串
for letter in letters:
im3 = im2.crop((letter[0], 0, letter[1], im.size[1]))
guess = [] # 记录和所有训练集的数据,用来排序
for image in imageset: # 和所有训练集的数据进行遍历
for x, y in image.items(): # x是正确名字,y是对应的[字典化图片]
if len(y) != 0: # y不为空,除去是Thumbs.db和.DS_Store训练出来的空列表
guess.append((v.relation(y[0], buildvector(im3)), x)) # y[0]就是字典化图片
guess.sort(reverse=True) # 从大到小排序
str += "{}".format(guess[0][1]) # 相似度最高的字符加到字符串里
if str == correct_name: #正确
success += 1 #正确次数加1
success_name_list.append(str) #记录正确的名字
else:
fail +=1 #错误次数加1
fail_name_list.append(str) #记录错误名字
correct_name_list.append(correct_name) #同时记录对应的正确名字用来进一步分析
count =0 #错误名字列表和对应的正确名字的下标一一对应
#统计出错误的原因
for letters in fail_name_list:
# 长度不统一
if len(letters) != len(correct_name_list[count]):
wrong_length_name.append(letters)
count+=1
#长度统一,但是识别错误
else:
index =0
for letter in letters:
if letter != correct_name_list[count][index]:
wrong_letter_count_dict[letter] = wrong_letter_count_dict.get(letter,0)+1
index+=1
else:
index+=1
count+=1
success_rate = success/(success+fail) #成功率
#打印总数,成功和失败的数量,以及成功率
print("total count = {}\n"
"success = {}, failed = {} \n"
" success_rate = {}\n".format(success+fail,success,fail,success_rate))
#打印成功的验证码的名字
print("Success Trainning name:")
for i in range(len(success_name_list)):
print(success_name_list[i])
wrong_length_count = len(wrong_length_name) #去除长度识别错误的数量
success_rate = success/(success+fail-wrong_length_count) #去除长度错误的图片后的成功率
#打印错误长度的验证码的数量
print("\nWrong Length count:{}".format(wrong_length_count))
print("total count without wrong length= {}\n"
"success = {}, failed = without wrong length = {} \n"
"success_rate without wrong length= {:.4f}\n".format(success+fail-wrong_length_count,
success,
fail-wrong_length_count,
success_rate))
#将字母识别错误>1的输出,用来表示标准样本的错误
wrong_letter_count_list = sorted(wrong_letter_count_dict.items(),
key = lambda x:x[1],
reverse =True)
for letter in wrong_letter_count_list:
if letter[1] >1:
print("Need more {} to train".format(letter[0]))







