1.安装第三方库(matplotlib,jieba,wordcloud,numpy)
1.1安装方法:pip命令在线安装(python3.x默认安装了pip,pip下载地址:https://pypi.python.org/pypi/pip#downloads)
已经配置好环境变量前提下,在cmd窗口直接运行:pip install 包名(应为我已经安装过了,所以提示已经安装过了),如 pip install numpy

1.2官网下载对应的whl进行安装
在 http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载所需的库的.whl文件,注意如果安装Python3.6,应下载对应的cp36的.whl文件,运行pip install **.whl
2. 导入对应的库
import matplotlib
import matplotlib.pyplot as plt #数据可视化
import jieba #词语切割
import wordcloud #分词
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS #词云,颜色生成器,停止
import numpy as np #科学计算
from PIL import Image #处理图片
3.主要实现代码
def ciyun():
#打开文本
textfile = open('1.txt').read() #读取文本内容
wordlist = jieba.cut_for_search(textfile)#切割词语
space_list = ' '.join(wordlist) # 链接词语
backgroud = np.array(Image.open('2.jpg')) #背景图片,只有黑白图才能按照形状生成词云
mywordcloud = WordCloud(width=1400, height=1200,
background_color= 'white',#背景颜色
mask=backgroud, #写字用的背景图,从图片中提取颜色
max_words=500, #最大词语数
stopwords=STOPWORDS,#停止的默认词语
font_path='simkai.ttf',#源码自带字体
max_font_size=100,#最大字体尺寸
random_state=50,#随机角度
scale=1).generate(space_list) #生成词云
image_color = ImageColorGenerator(backgroud)#生成词云的颜色
plt.imshow(mywordcloud) #显示词云
plt.axis('off') #关闭坐标(x,y轴)
#plt.savefig('4.png') #保存图片
plt.show()#显示
def main():
ciyun()
if __name__ == '__main__':
main()
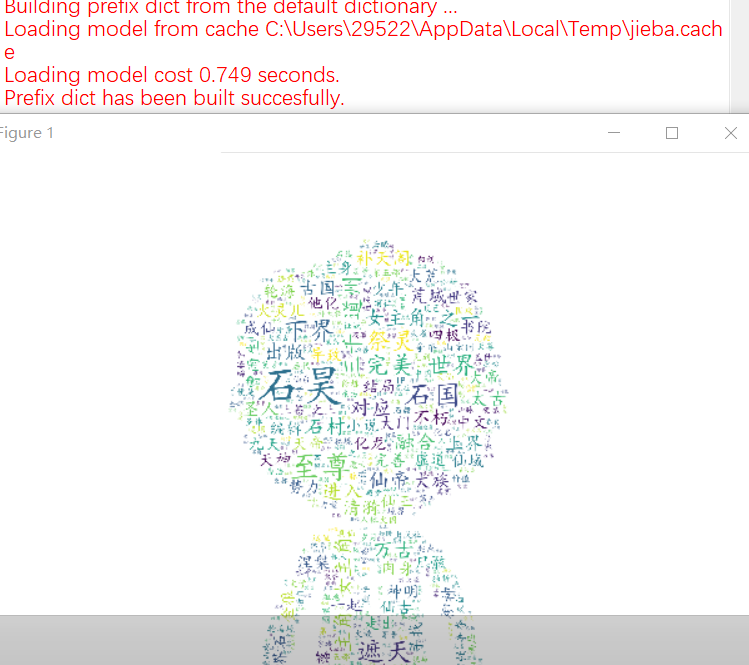
4.效果如下: