
本篇内容介绍了“jackson json序列化实现首字母大写,第二个字母小写的方法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
有这样一个类:
@Setter@Getter@JsonNaming(value = PropertyNamingStrategy.UpperCamelCaseStrategy.class)public class Student { private String bName;}序列化后,希望首字母大写,如下面的测试代码:
@Test public void contextLoads() throws IOException { Student test = new Student(); test.setBName("234234"); String s = objectMapper.writeValueAsString(test); Assert.assertEquals("{\"BName\":\"234234\"}", s); }可实际运行后,结果与希望不一样:
org.junit.ComparisonFailure:
Expected :{"BName":"234234"}
Actual :{"Bname":"234234"}
jackson在序列化时把第二个大写字母n转成了小写,这是为什么呢?
以下是跟踪源码的过程:
直接找到:com.fasterxml.jackson.databind.introspect.POJOPropertiesCollector#collectAll这个方法:
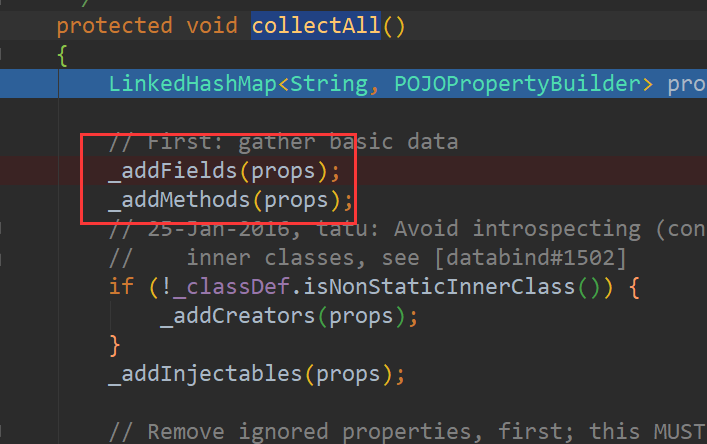
执行完_addFields(props)方法后:

执行完_addMethods(props)方法后:

一个是bName,一个是bname;
第一个bName取的是字段的名称,
第二个bname是取的它的set方法:
public static String okNameForIsGetter(AnnotatedMethod am, String name, boolean stdNaming) { if (name.startsWith("is")) { // plus, must return a boolean Class<?> rt = am.getRawType(); if (rt == Boolean.class || rt == Boolean.TYPE) { return stdNaming ? stdManglePropertyName(name, 2) : legacyManglePropertyName(name, 2); } } return null; }根据stdNaming来决定这个name是以什么标准输出,默认的是false;
stdManglePropertyName 就是原始输出。
legacyManglePropertyName 就是规范输出。
下面的代码就是规范输出:
protected static String legacyManglePropertyName(final String basename, final int offset) { final int end = basename.length(); if (end == offset) { // empty name, nope return null; } // next check: is the first character upper case? If not, return as is char c = basename.charAt(offset); char d = Character.toLowerCase(c); if (c == d) { return basename.substring(offset); } // otherwise, lower case initial chars. Common case first, just one char StringBuilder sb = new StringBuilder(end - offset); sb.append(d); int i = offset+1; for (; i < end; ++i) { c = basename.charAt(i); d = Character.toLowerCase(c); if (c == d) { sb.append(basename, i, end); break; } sb.append(d); } return sb.toString(); }主要逻辑在for循环中,去除set后,第一个字母小写,
第二字母小写后,与第二个字母比较,如果都是小写,则直接接上,返回,
如果第二字母大写,就如我们的这种情况,就以小写的情况,接上,再去找下一个字母,直到找到小写字母为止。
意思就是为了满足驼峰命名规则,要规范输出。
如果我们的字段命名正如它的规范的话,props是只有一条记录的,因为:名称相同,就不插入了,由于咱们的名称不同,所以就有两条记录。
protected POJOPropertyBuilder _property(Map<String, POJOPropertyBuilder> props, String implName) { POJOPropertyBuilder prop = props.get(implName); if (prop == null) { prop = new POJOPropertyBuilder(_config, _annotationIntrospector, _forSerialization, PropertyName.construct(implName)); props.put(implName, prop); } return prop; }可是我们输出中只有一条,没有bName这条,
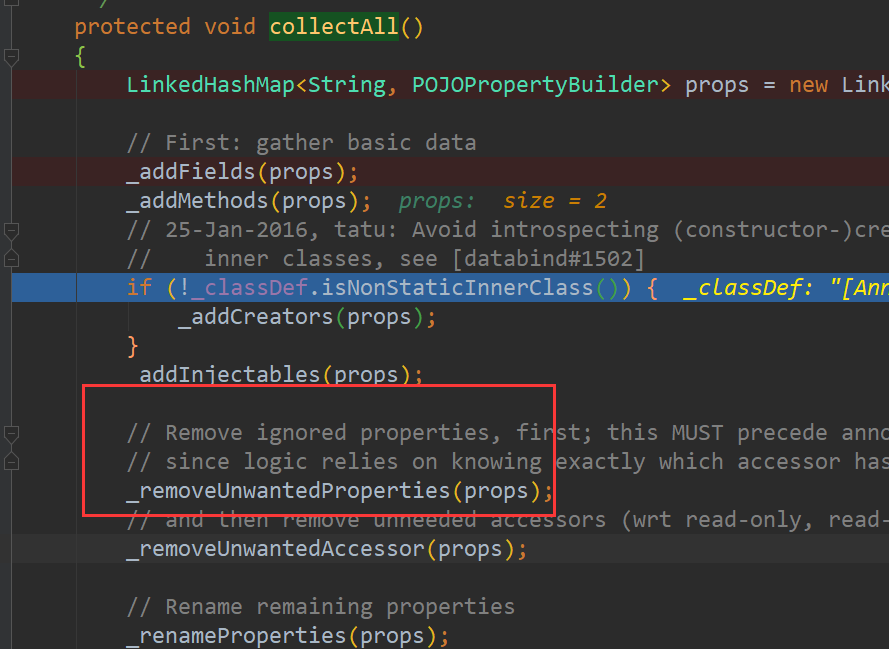
其实在是这里把第一条删除了。因为:
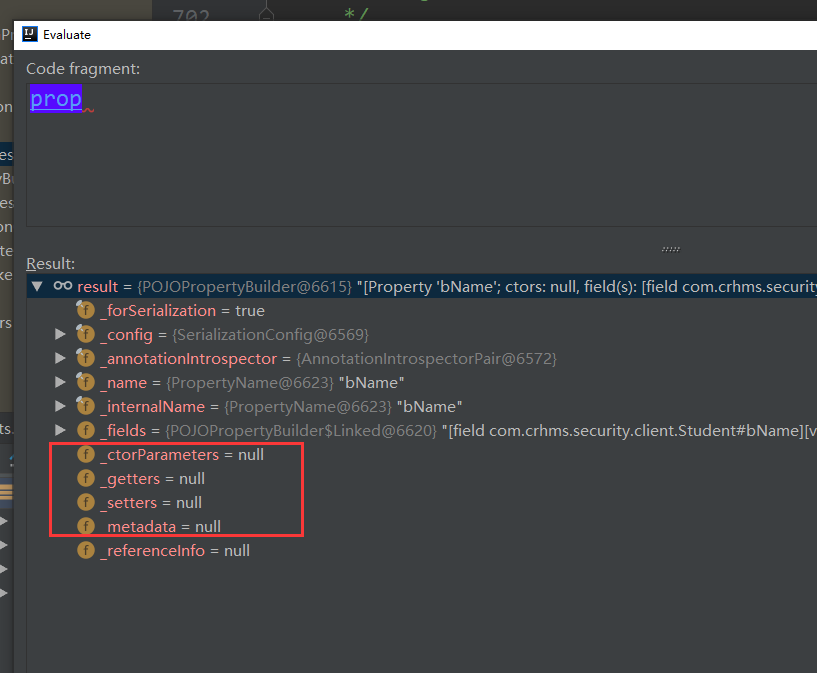
这些属性为空,导致这个字段不可见:
protected void _removeUnwantedProperties(Map<String, POJOPropertyBuilder> props) { Iterator<POJOPropertyBuilder> it = props.values().iterator(); while (it.hasNext()) { POJOPropertyBuilder prop = it.next(); // First: if nothing visible, just remove altogether if (!prop.anyVisible()) { it.remove(); continue; } // Otherwise, check ignorals if (prop.anyIgnorals()) { // first: if one or more ignorals, and no explicit markers, remove the whole thing if (!prop.isExplicitlyIncluded()) { it.remove(); _collectIgnorals(prop.getName()); continue; } // otherwise just remove ones marked to be ignored prop.removeIgnored(); if (!prop.couldDeserialize()) { _collectIgnorals(prop.getName()); } } } }只剩第二记录bname,再首字母大写,所以就是Bname了。
解决方案:
第一个就是JsonProperty
@Setter@Getter@JsonNaming(value = PropertyNamingStrategy.UpperCamelCaseStrategy.class)public class Student { @JsonProperty("BName") private String bName;}测试结果如下:
org.junit.ComparisonFailure:
Expected :{"BName":"234234"}
Actual :{"Bname":"234234","BName":"234234"}
虽然生成了BName,但是Bname仍在(加了JsonProperty就visable了)。
第二个就是配置objectMapper的MapperFeature.USE_STD_BEAN_NAMIN如上文提到了,非规范化输出。
如下代码:
@Test public void contextLoads() throws IOException { Student test = new Student(); test.setBName("234234"); objectMapper.configure(MapperFeature.USE_STD_BEAN_NAMING, true); String s = objectMapper.writeValueAsString(test); Assert.assertEquals("{\"BName\":\"234234\"}", s); }第三个方案:重写PropertyNamingStrategy:
@Test public void contextLoads() throws IOException { Student test = new Student(); test.setBName("234234"); //objectMapper.configure(MapperFeature.USE_STD_BEAN_NAMING, true); objectMapper.setPropertyNamingStrategy(new PropertyNamingStrategy() { private static final long serialVersionUID = 1L; // 反序列化时调用 @Override public String nameForSetterMethod(MapperConfig<?> config, AnnotatedMethod method, String defaultName) { return method.getName().substring(3); } // 序列化时调用 @Override public String nameForGetterMethod(MapperConfig<?> config, AnnotatedMethod method, String defaultName) { return method.getName().substring(3); } }); String s = objectMapper.writeValueAsString(test); Assert.assertEquals("{\"BName\":\"2342344\"}", s); }修改objectMapper的配置,要注意对其他功能的影响。
“jackson json序列化实现首字母大写,第二个字母小写的方法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!







