
本文小编为大家详细介绍“MySql主键id不推荐使用UUID的原因是什么”,内容详细,步骤清晰,细节处理妥当,希望这篇“MySql主键id不推荐使用UUID的原因是什么”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
规范
MySQL开发规范中经常可以看到:
推荐使用int,bigint 无符号做自增键
禁止使用uuid做主键
关于主键的类型选择上最常见的争论是用整型还是字符型的问题,关于这个问题《高性能MySQL》一书中有明确论断:
整数通常是标识列的最好选择,因为它很快且可以使用AUTO_INCREAMENT,如果可能,应该避免使用字符串类型作为标识列,因为很消耗空间,且通常比数字类型慢。
如果是使用MyISAM,则就更不能用字符型,因为MyISAM默认会对字符型采用压缩引擎,从而导致查询变得非常慢。
原因
通常主键 id 的数据类型有两种选择:字符串或者整数,主键通常要求是唯一的,如果使用字符串类型,我们可以选择 UUID 或者具有业务含义的字符串来作为主键。
对于 UUID 而言,它由 32 个字符+4 个’-'组成,长度为 36,虽然 UUID 能保证唯一性,但是它有两个致命的缺点:
不是递增的。MySQL 中索引的数据结构是 B+Tree,这种数据结构的特点是索引树上的节点的数据是有序的,而如果使用 UUID 作为主键,那么每次插入数据时,因为无法保证每次产生的 UUID 有序,所以就会出现新的 UUID 需要插入到索引树的中间去,这样可能会频繁地导致页分裂,使性能下降。
太占用内存。每个 UUID 由 36 个字符组成,在字符串进行比较时,需要从前往后比较,字符串越长,性能越差。另外字符串越长,占用的内存越大,由于页的大小是固定的,这样一个页上能存放的关键字数量就会越少,这样最终就会导致索引树的高度越大,在索引搜索的时候,发生的磁盘 IO 次数越多,性能越差。
对于整数的数字类型,MySQL 中主要有 int 和 bigint 类型。其中 int 占用 4 个字节,bigint 占用 8 个字节,这和 Java 中的 int 和 long 对应。如果使用无符号的 int 类型作为主键,那么主键的最大值为 2^32-1,即 4294967295,这个值不到 43 亿,似乎有点太小了。虽然一张表的数据,我们不可能让其达到 43 亿条(太大会影响性能),但是对于频繁进行插入、删除的表来说,43 亿这个值是可以达到的。而如果使用无符号的 bigint 类型的话,主键的最大值可以达到 2^64-1,这个数足够大了,如果以每秒插入 100 万条数据计算的,58 万年以后才能达到最大值。所以 bigint 作为主键的数据类型,完全不用担心超过最大值的问题。
而强制要求主键 id 是自增的,则是为了在数据插入的过程中,尽可能的避免索引树上页分裂的问题。
关于主键是聚簇索引,如果没有主键,InnoDB会选择一个唯一键来作为聚簇索引,如果没有唯一键,会生成一个隐式的主键。
隐式主键:
InnoDB会自动帮你创建一个不可见的、长度为6字节的row_id,而且InnoDB维护了一个全局的dictsys.row_id,所有未定义主键的表都会共享该row_id,每次插入一条数据都把全局row_id当成主键id,然后全局row_id加1。
该全局row_id在代码实现上使用的是bigint unsigned类型,但实际上只给row_id保留了6字节,所以这种设计就会存在一个问题:如果全局row_id一直涨,直到2的48次幂-1时,这个时候再加1,row_id的低48位都会变为0,如果再插入新一行数据时,拿到的row_id就为0,这样的话就存在主键冲突的可能,所以为了避免这种隐患,每个表都需要一个主键。
详解-重点:
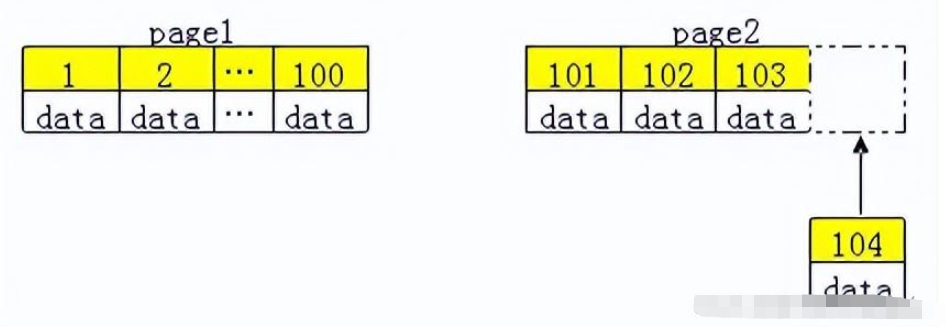
InnoDB引擎使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL 会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
所以在使用innoDB表时要避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是针对I/O密集型的应用。例如:从性能角度考虑,使用UUID的方案就会导致聚簇索引的插入变得完全随机。
理论总结:
自增的主键的值是顺序的,所以 Innodb 把每一条记录都存储在一条记录的后面。
当达到页面的最大填充因子时候 ( innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的修改):
1)下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
2)新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗
3)减少了页分裂和碎片的产生
选择 主键id:
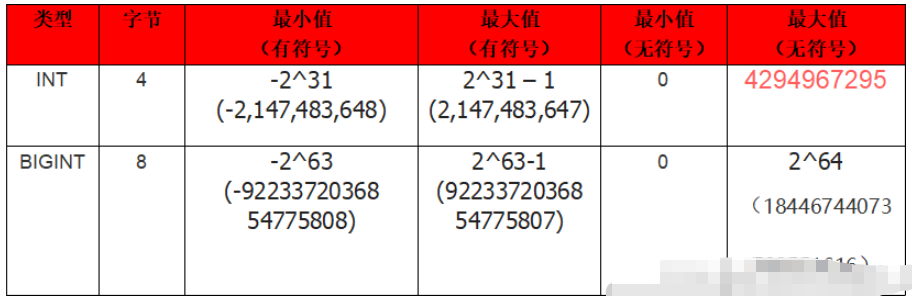
tinyint、smallint、mediumint,这三个不常用就不说了。无符号是设置了 unsigned 属性,表示不允许负值,这大致可以使正数的上限提高一倍。
以无符号int类型为例,42亿虽然看起来是个很大的数字,但是对于一些插入删除很频繁的业务来说,并非无法触达这个上限。特别是有的业务表设置的步长比较大,会导致id自增的速度更快。如果你的业务预期会产生很多数据,那么建议你在创建表时,直接使用bigint。
因为MySQL的主键策略:id自增值达到上限以后,再申请下一个 id 时,仍然是最大值。
如果bigint真的还不够使用的话,我们可以使用雪花算法生成的id做主键,由于其也是大致递增的,对性能也不会产生影响,只需要由bigint改成更大范围的decimal就行。
UUID:
一:使用场景
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。在UUID的算法中,可能会用到诸如网卡MAC地址,IP,主机名,进程ID等信息以保证其独立性
二:有的开发就是喜欢使用UUID怎么办?
所以MySQL8.0也是顺应时代潮流,担负时代的革命重任,MySQL8.0也对uuid的存储做了进一步的提升。整体上看MySQL8.0现在的重点方向也是对开发的友好度支持上。
结论:
在MySQL8.0中还是推荐使用无符号的int, bigint做主键,如果要使用uuid可以建一个唯一索引
MySQL和Java两者默认生成的uuid是version 1格式:datetime|mac地址,因为高低位顺序乱了,造成顺序乱掉,可以使用MySQL的函数uuid_to_bin(@uuid,1) , bin_to_uuid(@uuid,1)进行调整转换,实现有序化
对于使用uuid_to_bin转化后的uuid存储,使用binary(16)或是varbinary(16)替代varchar(36),从而实现从36byte降到16byte。
这个技巧不是万能的,如果你的数据库CPU是瓶颈,使用转化存储,可能带来CPU上更重的开销,反之,如果你的IO是瓶颈,但CPU有较大的空闲,使用这个技巧就是一个不错的优化方案。如果不好把握,就用你可以用得到的最好硬件就可以了,一般情况下如果用上SSD后IO都没啥问题,但也可以使用这个技术去降低表的物理大小。
实战:
环境准备
在MySQL 5.7中分别创建三张数据表:
test_varchar:以UUID作为主键。
test_long:以bigint作为主键。
test_int:以int作为主键。
三个表的字段,除了主键ID 分别采用varchar,bigint 和自动增长int不同外,其他三个字段都为 varchar 36位
另外,建表时使用InnoDB存储引擎,并且向数据库中插入100W条数据,用以测试。
压测信息
表类型:InnoDB
数据量:100W条
数据库:
主键采用uuid 32位
运行查询语句1:SELECT COUNT(id) FROM test_varchar;运行查询语句2:SELECT * FROM test_varchar WHERE vname='71e88bab-2f0f-6811-89ff-4cc935c075d8';运行查询语句3:SELECT * FROM test_varchar WHERE id='00004599b05211e196aa002655b28d7b';三条查询语句的耗时分别如下所示:
语句1消耗时间平均为:2.81秒;
语句2消耗时间平均为:3.11秒;
语句3消耗时间平均为:0秒;(多方测试,条件里只要有主键ID,查询速度毫秒级都显示000。测试的ID值,有前一百条的,也有后90多万条的。查询时间完全一样,毫秒级都为000)
主键采用bigint
主键采用bigint,使用uuid_short()产生数据,数据为有序列的纯数字(22461015967875697)。(其相当于自动增长,只是固定的基数值较大而已。)
运行查询语句1:SELECT COUNT(id) FROM test_long;运行查询语句2:SELECT * FROM test_long WHERE vname='63b10f80-0e20-28cc-3078-d7331ba410b6';运行查询语句3:SELECT * FROM test_long WHERE id='22461015967875702';三条查询语句的耗时分别如下所示:
语句1消耗时间平均为:1.31秒;
语句2消耗时间平均为:1.51秒;
语句3消耗时间平均为:0秒;(多方测试,条件里只要有主键ID,查询速度毫秒级都显示000。测试的ID值,有前一百条的,也有后90多万条的。查询时间完全一样,毫秒级都为000)
主键采用自增int
运行查询语句1:SELECT COUNT(id) FROM test_int;运行查询语句2:SELECT * FROM test_int WHERE vname='908b57a5-cdef-32d1-0320-e14209b08894';运行查询语句3:SELECT * FROM test_int WHERE id=900002;其中,主键采用mysql自带的自动增长,数据为纯数字(1,2,3,4,5……)。
三条查询语句的耗时分别如下所示:
查询语句1消耗时间平均为:1.20秒;
查询语句2消耗时间平均为:1.41秒;
查询语句3消耗时间平均为:0秒;(多方测试,条件里只要有主键ID,查询速度毫秒级都显示000。测试的ID值,有前一百条的,也有后90多万条的。查询时间完全一样,毫秒级都为000)
新增:
UUID做主键,其他字段相同,插入100万条数据,用了2.5个小时
自增主键,其他字段相同,插入相同的100万条数据,用了26分钟
读到这里,这篇“MySql主键id不推荐使用UUID的原因是什么”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网行业资讯频道。








